Merge 46419f642c into 59bafb8d4d
This commit is contained in:
commit
54bd65788e
|
|
@ -0,0 +1,490 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"source": [
|
||||
"\r\n",
|
||||
"*Note:Above picutres source from Internet *\r\n",
|
||||
"\r\n",
|
||||
"# 1. OCR Background\r\n",
|
||||
"## 1.1 OCR Application Scenario\r\n",
|
||||
"\r\n",
|
||||
"* **<font color=red>What is OCR</font>**\r\n",
|
||||
"\r\n",
|
||||
"OCR(Optical Character Recognition)is one of application branch at computer vision. The OCR application scope is tradition defintion is object-oriented scan documents,Now OCR regular application area is STR(Scene Text Recognition) that is object-oriented \r\n",
|
||||
"natural scenario, such as below pictures that is natural visiable words.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"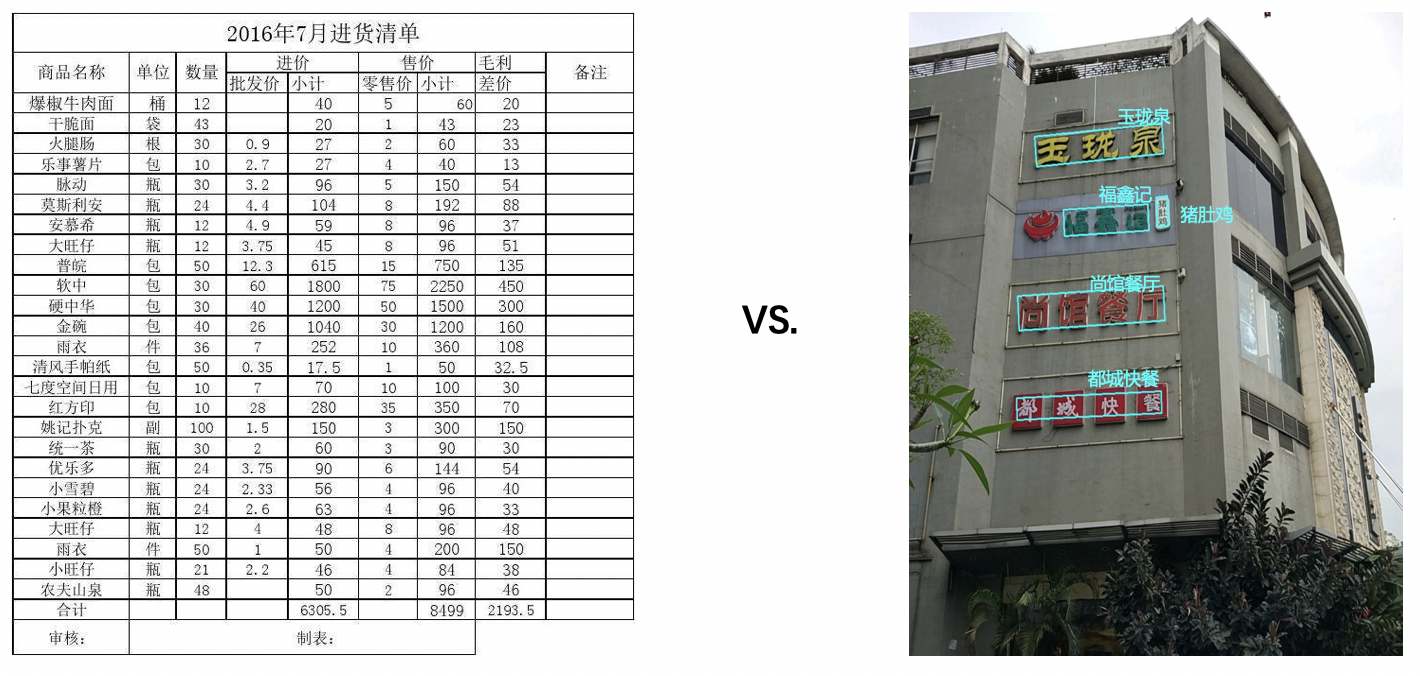\r\n",
|
||||
"<center>Figure1 Document scenario word recognition VS. Natural scenario word recognition </center> \r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"\r\n",
|
||||
"* **<font color=red>What is OCR application OCR scenario?</font>**\r\n",
|
||||
"\r\n",
|
||||
"OCR technology has rich application scenario. one of classics OCR application scenario is vertical-oriented of structuring text recognition, such as License plate recognition、bank card infromation recognition、ID card information recognition、ticket information recognition etc. These vertical-oriented OCR application has common features is fixed-fomat, that means applition OCR technology will automatic those jobs ,that will reduce human resource cost and improve work efficiency. \r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"Recentlly OCR application focus at vertical-oriented of structuring text recognition\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure2 OCR application scenario</center>\r\n",
|
||||
"\r\n",
|
||||
"Beside of vertical-oriented of structuring text recognition. The general OCR technology also has wide range applicaction mode and usually combine with other area technology for handle multi-mode task, such video scenario using OCR technology doing Automatic subtitle translation、security monitoring etc, or combine with video frame features for understanding video content、 searching video frame. \r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure3 General OCR of multi-mode task</center>\r\n",
|
||||
"\r\n",
|
||||
"## 1.2 OCR technology challenge\r\n",
|
||||
"OCR technology challenge from algorithm layer and application layer.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"* **<font color=red>Algorithm layer</font>**\r\n",
|
||||
"\r\n",
|
||||
"OCR has rich application scenario, that means will exists a lot of diffficutly technology point. This article put 8 kinds technology questions:\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>图4 OCR Algorithm layer technical point</center>\r\n",
|
||||
"\r\n",
|
||||
"The Text detection and text recognition's technical challenge from those questions. It can be understanding that us from nutural scenario, Currently academic community is focus on OCR \r\n",
|
||||
"*Note:Above picutres source from Internet *\r\n",
|
||||
"\r\n",
|
||||
"# 1. OCR Background\r\n",
|
||||
"## 1.1 OCR Application Scenario\r\n",
|
||||
"\r\n",
|
||||
"* **<font color=red>What is OCR</font>**\r\n",
|
||||
"\r\n",
|
||||
"OCR(Optical Character Recognition)is one of application branch at computer vision. The OCR application scope is tradition defintion is object-oriented scan documents,Now OCR regular application area is STR(Scene Text Recognition) that is object-oriented \r\n",
|
||||
"natural scenario, such as below pictures that is natural visiable words.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure1 Document scenario word recognition VS. Natural scenario word recognition </center> \r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"\r\n",
|
||||
"* **<font color=red>What is OCR application OCR scenario?</font>**\r\n",
|
||||
"\r\n",
|
||||
"OCR technology has rich application scenario. one of classics OCR application scenario is vertical-oriented of structuring text recognition, such as License plate recognition、bank card infromation recognition、ID card information recognition、ticket information recognition etc. These vertical-oriented OCR application has common features is fixed-fomat, that means applition OCR technology will automatic those jobs ,that will reduce human resource cost and improve work efficiency. \r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"Recentlly OCR application focus at vertical-oriented of structuring text recognition\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure2 OCR application scenario</center>\r\n",
|
||||
"\r\n",
|
||||
"Beside of vertical-oriented of structuring text recognition. The general OCR technology also has wide range applicaction mode and usually combine with other area technology for handle multi-mode task, such video scenario using OCR technology doing Automatic subtitle translation、security monitoring etc, or combine with video frame features for understanding video content、 searching video frame. \r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure3 General OCR of multi-mode task</center>\r\n",
|
||||
"\r\n",
|
||||
"## 1.2 OCR technology challenge\r\n",
|
||||
"OCR technology challenge from algorithm layer and application layer.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"* **<font color=red>c</font>**\r\n",
|
||||
"\r\n",
|
||||
"OCR has rich application scenario, that means will exists a lot of diffficutly technology point. This article put 8 kinds technology questions:\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure4 OCR Algorithm layer technical point</center>\r\n",
|
||||
"\r\n",
|
||||
"The Text detection and text recognition's technical challenge from those questions. It can be understanding that us from nutural scenario, Currently academic community is focus on OCR nutural scenario.As for the above problems the recognition will difficult rather than detection.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"* **<font color=red>Application layer</font>**\r\n",
|
||||
"In practically OCR regrular application mode besdide of abolve chapter conclusion algorithm layer problem list such Affine transformation, scale problems, insufficient lighting, fuzzy shooting etc.The OCR application layer also exist 2 problems:\r\n",
|
||||
"1. **OCR real-handle at Big-data** Usually OCR application need facing handle huge data,We need data can be real-time process,The mode feedback response time is big problem.\r\n",
|
||||
"2. **The End-side applicaion need OCR mode is lightly, recognition sppeed is on time** The OCR application deploy nned take on mobile side or embedded hardware, In usually there are 2 modes End-side OCR deploy mode: upload to server vs. End-side direct recognition, That consider upload server handle needs network traffic,low real-time respone ,server-side workload will high when \r\n",
|
||||
"concurrent requests too large and data security problems.So we proposals at End-sides deploy and handle OCR recognition, also it will facing storge space and computation resoure limit that will the OCR mode size and predict speed has constraint. \r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"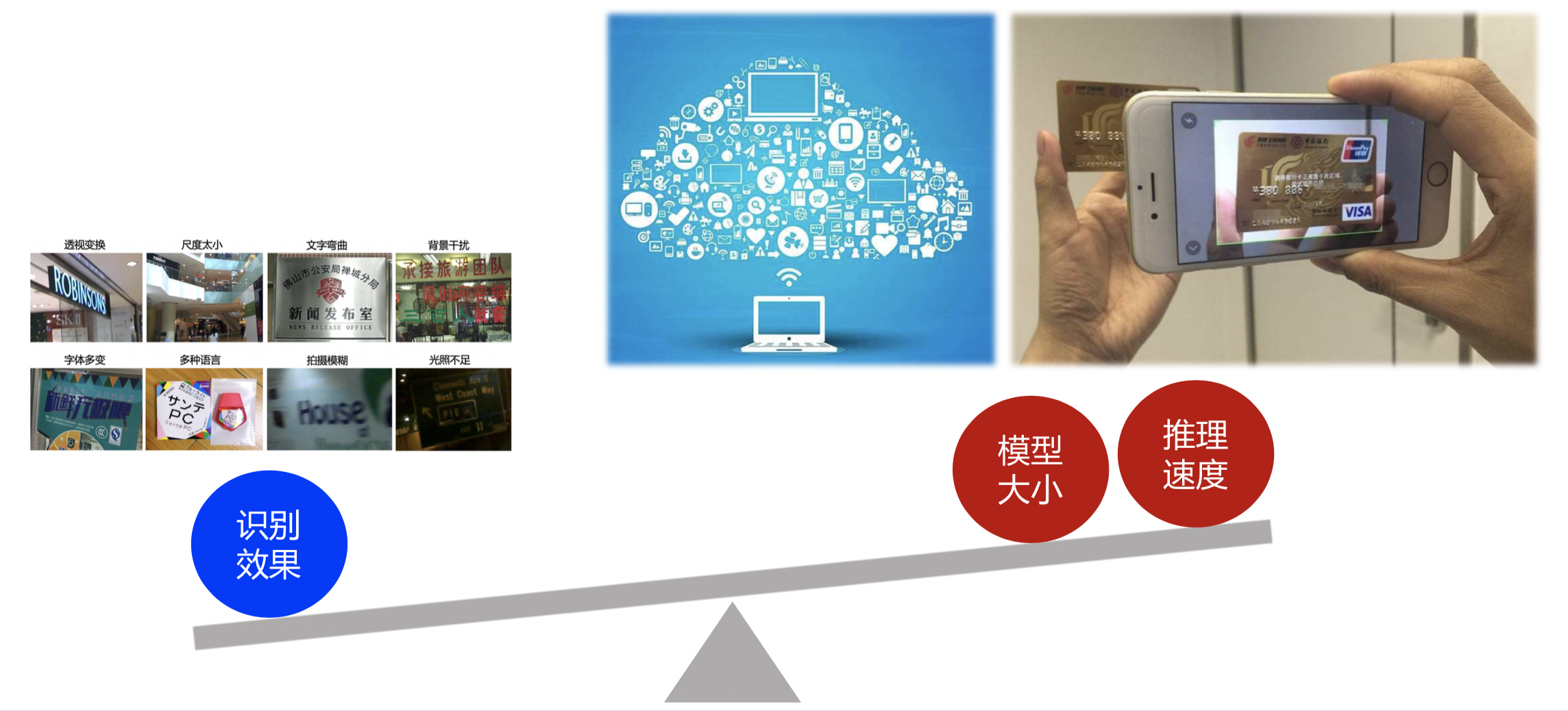\r\n",
|
||||
"<center>Figure5 OCR application layer points</center>\r\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"source": [
|
||||
"# 2. OCR frontier algorithm\r\n",
|
||||
"\r\n",
|
||||
"Although OCR is a relative to the specific's jobs, howerver that involve with multi-sides technique include Text detection、Text recognition、End-to-End text recognition、Document analysis etc. In academic community side related OCR technique research result is upstrems.As below will introduce some critical points about OCR. \r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"## 2.1 Text detection\r\n",
|
||||
"\r\n",
|
||||
"Text detection is focus on locate with input images's text area.In recentlly years about text detection reearch is full rich at In academic community, one roadmap text detection is one of target detection instance,that base on improve target detection algorithm\r\n",
|
||||
"for text detection,such as TextBoxes[1] is base on one-phase target detection SSD[2] algorithm, resize target text box for long-text line size,CTPN[3] is base on Faster RCNN[4] is from improve structured.Howerver text detection not same as target detection, such text is width and height usually too large,it seems like \"bar sharp\",may be text line gaps is closely,curve texts etc. so it has raise specials algorithm for text detection, such as EAST[5]、PSENet[6]、DBNet[7] etc.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center><img src=\"https://ai-studio-static-online.cdn.bcebos.com/548b50212935402abb2e671c158c204737c2c64b9464442a8f65192c8a31b44d\" width=\"500\"></center>\r\n",
|
||||
"<center>Figure6 Sample of text detection</center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"Currently more popularly text detection algorithm is **Base on regression**和**Base on split**, some of algorithm is combine 2 kinds logic. Base on regression is reference object detection algorithm, that setup anchor text box or direct pix regression,this \r\n",
|
||||
"method is fine for regular text detection, but non-regular text detection is not fine,eg CTPN[3] at horizontal line text detection performnce is fine,but not good with incline 、curve text detection.SegLink[8] is good with long text line mode,but low performance with sparse text; Base on split algorithm import Mask-RCNN[9], those algorithms facing all kind of sharps text detection performance will up to better level, but one of weakness is so complex which cause response performance problems and it not resolve \r\n",
|
||||
"overlap text detection issues.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center><img src=\"https://ai-studio-static-online.cdn.bcebos.com/4f4ea65578384900909efff93d0b7386e86ece144d8c4677b7bc94b4f0337cfb\" width=\"800\"></center>\r\n",
|
||||
"<center>Figure7 Overview of text detection algorithm</center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"\r\n",
|
||||
"|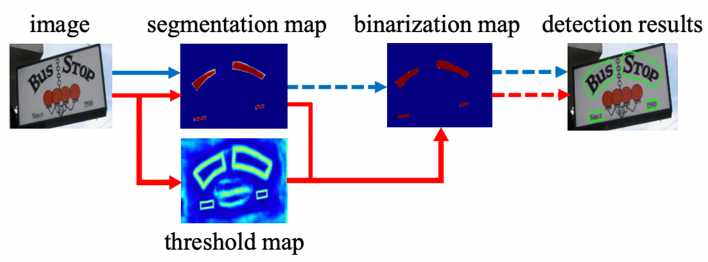|\r\n",
|
||||
"|---|---|---|\r\n",
|
||||
"<center>Figure8 (Left)Base on regression CTPN[3] optimize anchor (Middle)Base on split DB[7] optimize result (Right)Regression+Split SAST[10]</center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"About text detection detail description will introduce at chapter 2\r\n",
|
||||
"\r\n",
|
||||
"## 2.2 Text Recognition\r\n",
|
||||
"Text Recognition's main target is identify image text content, In generally Text Recognition is obtain images text area contents that from text detection result. According to Text Recognition methods that 2 class on that **Regular Text Recognition** and **Non-Regular Text Recognition**.Regular Text Recognition is print font、scan font,The text nera with horizontal line; Non-Regular Text Recognition usually position not near with horizontal line,that exist curve、mask、indistinct etc issues. Non-Regular Text Recognition has a big challenging, also is main OCR research area. \r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure9 (Left)Regular Text Recognition VS. (Right)Non-Regular Text Recognition</center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"\r\n",
|
||||
"There are CTC and Sequence2Sequence kinds for Regular Text Recognition that base on ecoding mode. That is deep learning sequence features convert to finally recognition output is diffenence. Base CTC algorithm represent is CRNN[11].\r\n",
|
||||
"\r\n",
|
||||
"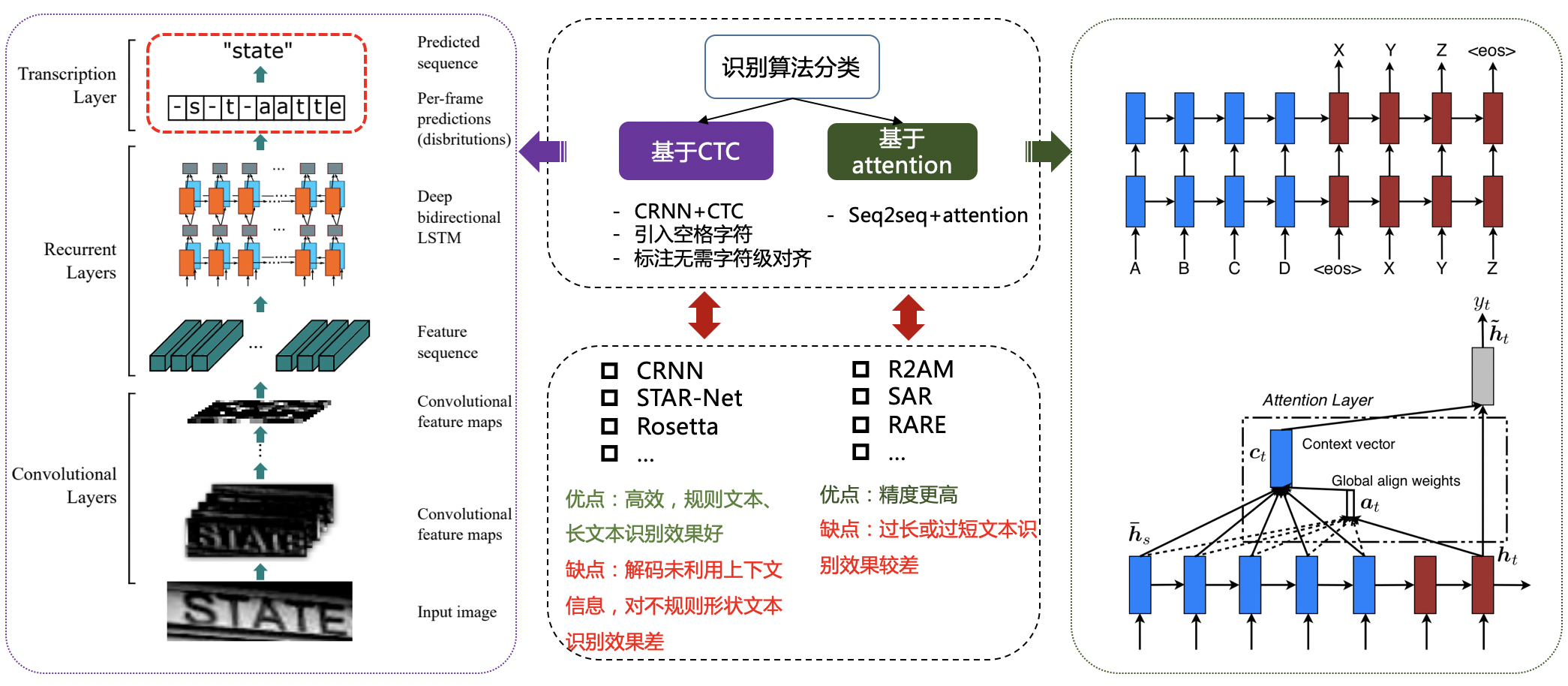\r\n",
|
||||
"<center>Figure10 CTC Recognition algorithm VS. Attention Recognition algorithm</center>\r\n",
|
||||
"\r\n",
|
||||
"Non-Regular Text Recognition algorithm kinds is richer. Like STAR-Net[12] is addition TPS correction module that convert Non-Regular to Regular for Text Recognition; RARE[13] is Attention roadmap that enhance sequences attention; Base on split mode that split text line for each chars and compare with whole text line doing recognition, that is identify single chars is easy;\r\n",
|
||||
"Recentlly Transfomer[14] is quickly growing and obtain valid check at all kinds tasks, that is make some base on Transformer Text Recognition algorithm,This method using transformer structure for resolve CNN problem at long dependency mode building.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure11 Base on Split mode Text Recognition algorithm[15]</center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"\r\n",
|
||||
"Text Recognition deatil will put on chapter 3\r\n",
|
||||
"\r\n",
|
||||
"## 2.3 Structure-Document Recognition\r\n",
|
||||
"\r\n",
|
||||
"In tradition that OCR can resolve text detection and recognition request, but in OCR practical that need data is structure, eg ID card、invoice information extract,Table structure recognition,express document、contract content compare、insurance document information compare etc. The OCR result + after process is commonly structure solution,but the process logic is complex, and after process part need detail design, generalization performance is low. Now OCR is in mature period,that is structure information extract request is usually that is Layout analysis、 Table Recognition、Key Information Extraction etc smart document analysis technical is become more popular and focus.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"* **Layout Analysis**\r\n",
|
||||
"Layout Analysis is focus on document image content classification.The classification is pure-text、title、table、image etc.Usually that will make some layout tags for detection and recognition in documents,eg Soto Carlos[16] apply on target detection that base on\r\n",
|
||||
"Faster R-CNN,combine with content information and using documents posisition for improve text detection performance; Sarkar Mausoom[17] et al. proposed a prior-based segmentation mechanism that train document split mode under high resolution images which is resolve difficult on split and merge issue on narrow-resize orign-images that is dense tags. \r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure12 Layout Analysis Diagram</center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"\r\n",
|
||||
"* **Table Recognition**\r\n",
|
||||
"Table Recognition is recognition and convert document's table to Excel.The text image table is many kinds,eg row-col merge,various cells type, Beside those also document layout and photo light is rise huge challenge. These challenge cause Table Recognition is difficut point on document understand area. \r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure13 Table Recognition Diagram </center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"There are many roadmap on Table Recognition,early is base on traditional algorithm for heuristic rules,Such as T-RECT algorithm proposed by Kieninger et al. [18],Usually is config rules for human,connected domain detection analysis and processing;Recently years that deep learning is popular that is appears base on CNN's Table Recognition methods, eg Siddiqui Shoaib Ahmed[19] propose base on DeepTabStR,Raja Sachin[20] propose TabStruct-Net;In addition Graph Neural Network is mature,some researchers try to Graph Neural Network apply on Table Recognition, base on Graph Neural Network area is re-building Graph works for Table Recognition,eg\r\n",
|
||||
"Xue Wenyuan[21] is propose TGRNet; End-to-End method direct using network understand table structure and show output HTML.Most End-to-End methods using Seq2Seq, eg Attention and Transformer such as TableMaster[22].\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"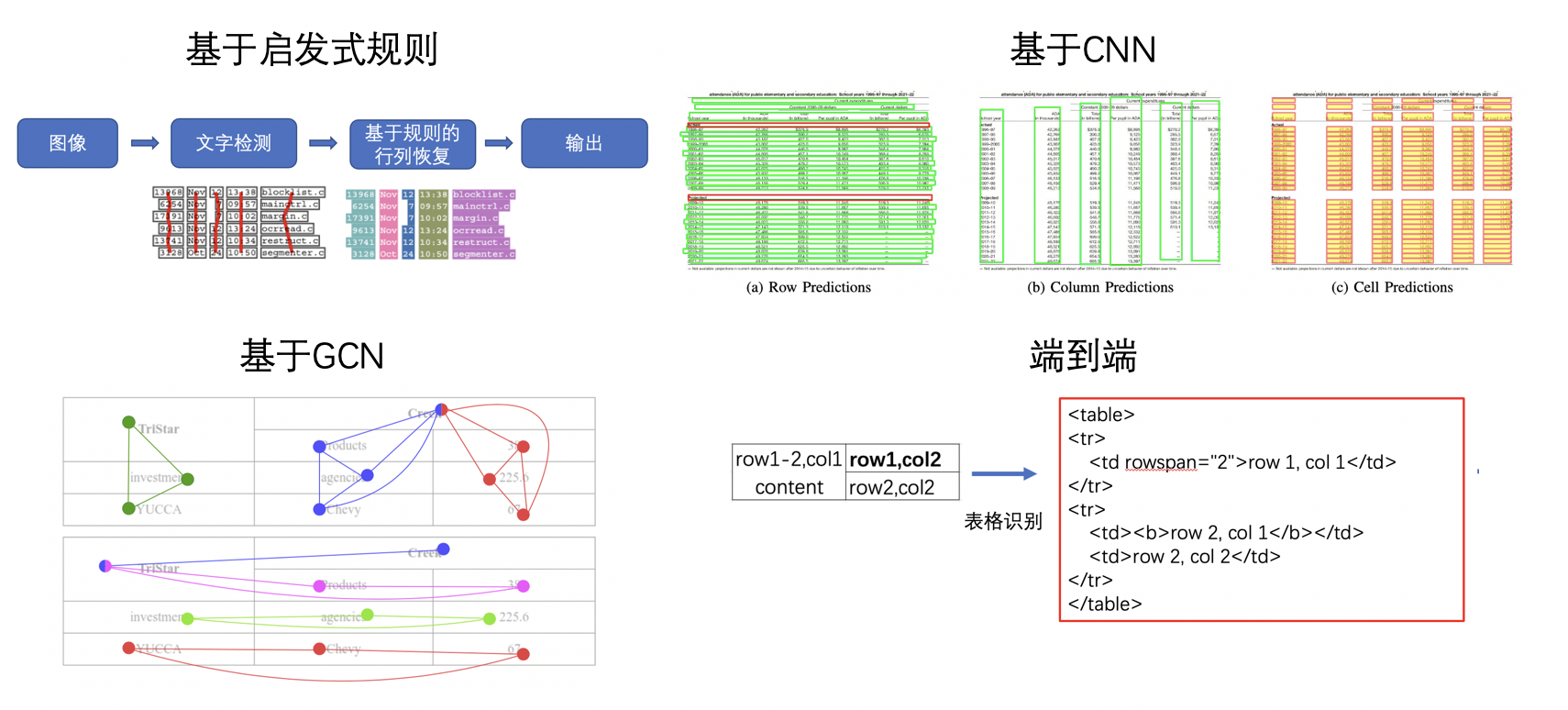\r\n",
|
||||
"<center>Figure14 Table Recognition Method Diagram</center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"\r\n",
|
||||
"* **Key Information Extraction**\r\n",
|
||||
"Key Information Extraction is important tasks on Document VQA,that is Extract informtion from images, eg extract name and Id card No from ID cards, those information is fixed on special task and differcnce with difference tasks.\r\n",
|
||||
"\r\n",
|
||||
"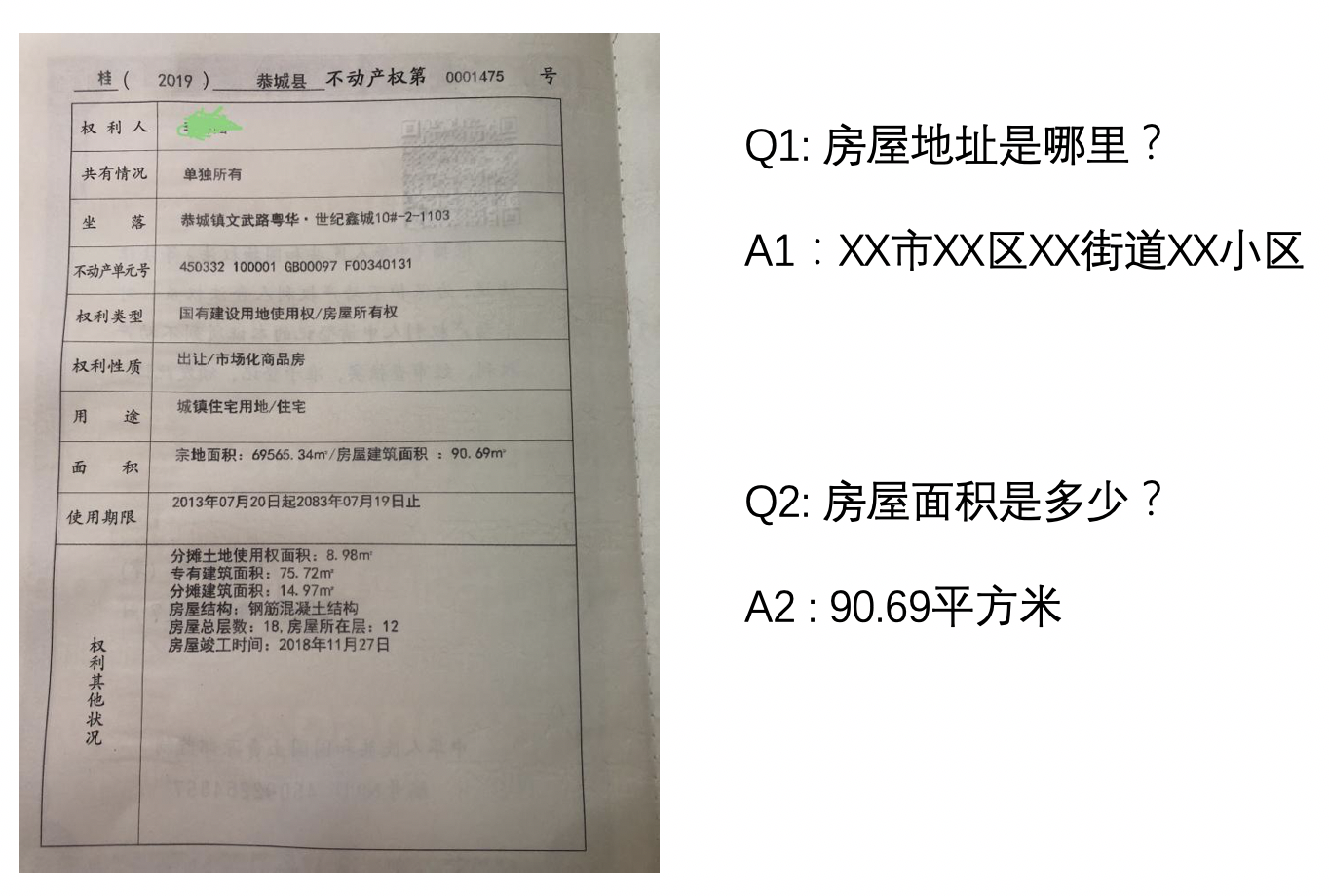\r\n",
|
||||
"<center>Figure15 DocVQA Diagram</center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"KIE 2 sub-tasks:\r\n",
|
||||
"\r\n",
|
||||
"- SER: Semantic Entity Recognition,that is text classification foe each detection text area.eg c name , ID card, from below image blank frame and red frame.\r\n",
|
||||
"- RE: Relation Extraction,that is text classification foe each detection text,eg identify question and answer.such as below red frame and blank frame is menas question and answer, yellow line means relation with question and answer. \r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure16 ser and re task</center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"In generally KIE is base on Named Entity Recognition,NER[4] for research, but this methos only using text information on image,lack of vision and structure information apply,which cause precision is low.Base on this,In recentlly year will take vision 、structure information to text information, According to mulit-mode information concepts that can get as below 4 roadmaps:\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"- Base on Grid \r\n",
|
||||
"- Base on Token\r\n",
|
||||
"- Base on GCN\r\n",
|
||||
"- Base on End to End\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"\r\n",
|
||||
"The document analysis will introduce at Chapter 6.\r\n",
|
||||
"\r\n",
|
||||
"## 2.4 Other Technique\r\n",
|
||||
"\r\n",
|
||||
"As above is introduce OCR area 3 critical technique:Text detection、Text Recognition、Structure-Document Recognition,other more OCR technique that include End-to-End text recognition、OCR image pre-process、OCR data merge etc, that reference Chapter 7 and Chapter 8.\r\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"source": [
|
||||
"# 3. OCR Industry Practice\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"> If you are Wang,How can do that? \r\n",
|
||||
"> 1. I can not,I did not it,I am leaving😭\r\n",
|
||||
"> 2. The suggest manager outsource or business solution ,That charge compay funds😊\r\n",
|
||||
"> 3. Find same case at Internet ,Oriented Github programing😏\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"\r\n",
|
||||
"Finally OCR technique will apply to Industry. Althought OCR technique academic's researchs is full,OCR technique business appliction is popular rather than others AI technique, howerver actually also exists some of trouble and issues. As below will take technique and Industry two views for anlysis.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"## 3.1 Industry Practice Keynotes\r\n",
|
||||
"\r\n",
|
||||
"In actually, developer will base on open source community start or push project, the deveoper apply open source mode will facing 3 difficult point:\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure17 3 difficult point on OCR Industry Practice</center>\r\n",
|
||||
"\r\n",
|
||||
"**1. Can not find、 Can not choice**\r\n",
|
||||
"The rich resources on open source community,but information dissymmetry which cause low efficiency support developer. One hand,open source community resource is too manys,the developer facing request,difficult with choice better project fron huge code repository.\r\n",
|
||||
"That means \"Can not find\" problem; other hand,at chcoice mode,Open English dataset index did not give direct reference on chinese environment, case by case check and confirm need take long time and humans and it not make sure this is best choice,that is \"Can not choice\".\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"**2. did not match Industry**\r\n",
|
||||
"Open source community always focus on performance tunning,eg academic paper's code open source or reproduction,In generally that is keen on at algorithm output performance, balance with mode size and speed is lack,but mode size and predict Time-consuming is criticacl index at industry.At serve-side and mobile-side,need recognize images is manys that means mode size need become lighting and precision index is better,predict respone is faster. GPU is too expensive,using CPU running is economics. Before satisfy business condition, the mode is light that means calculcation resource is small.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"**3. Difficult with Tuning and optimize 、Trouble with traing and deploy mode**\r\n",
|
||||
"That always can not meet take bussiness requirement by direct using open source code,Actually apply OCR will facing a lot of problems,personalized business requirement that means need take user-difined data set for re-training,Currently check open source project output result is high cost. In addition OCR apply scene is full, the application cover to server side and moblie devices,\r\n",
|
||||
"hardware environment is difference which means need support solution is totally. Unfortunately keen on algorithm and mode from open\r\n",
|
||||
"source community,a lack of predict parts supports that means the developer need consider algorithm and engineering apply OCR from paper to scene sites. \r\n",
|
||||
"\r\n",
|
||||
"## 3.2 Industrial OCR development Suites PaddleOCR\r\n",
|
||||
"OCR Industrial practice need total solution full all life circle for rapid research and develop speed, saving develop time. As other words that super-light mode and full life circle soulution special for limition at calculate 、storge space resouces's moblie 、embeding devices is necessary.\r\n",
|
||||
"\r\n",
|
||||
"In this background, Industrial grade OCR development suites [PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR) is appear.\r\n",
|
||||
"\r\n",
|
||||
"PaddleOCR's roadmap is from user images and requirerment that base on Paddle core framework which choice rich leading algorithm for apply to Industry's PP styles models and make to inference.PaddleOCR provvide manys predict deploys that is fine for differencce needs. \r\n",
|
||||
"\r\n",
|
||||
"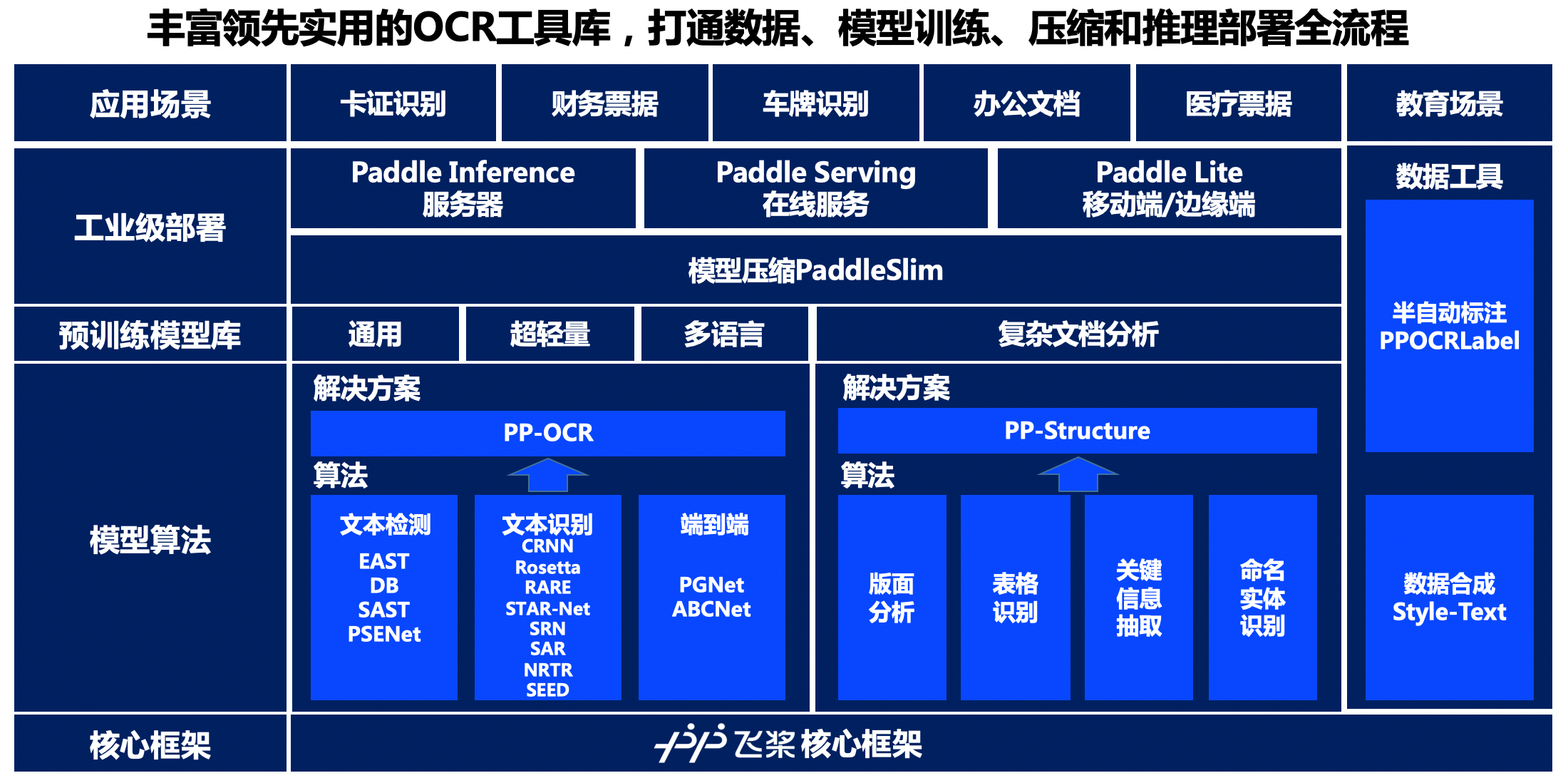\r\n",
|
||||
"<center>Figure18 PaddleOCR development Digram</center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"It can be see from digram that PaddleOCR base on Paddle core framework,There are rich-solutions at model algorithm、predict-train model、Industrial deployment and also provide data merge,semi-auto data marks which will satisfy end developer make data requeirements. \r\n",
|
||||
"\r\n",
|
||||
"**Model algorithm layer**,PaddleOCR has provide **Text detection and recognotion** and **structure document analysis** 2 kinds tasks's solution.At Text detection and recognotion side,PaddleOCR recurrence or open source 4 kinds Text detection algorithm、8 kinds Text recognotion algorithm、1 kind End-to-End Text detection algorithm,and base on those develop PP-OCR series common Text detection and recognotion solution; At structure document analysis side,PaddleOCR provvide layout analysis、Table recognotion、Key information Extraction、Named Entities etc, base on above foundation made PP-Structure document analysis solution. The refine algorithm can be satisfaction with developer at various of business requirements, the code framework also easy for developer doing compare with algorithm and performance.\r\n",
|
||||
"\r\n",
|
||||
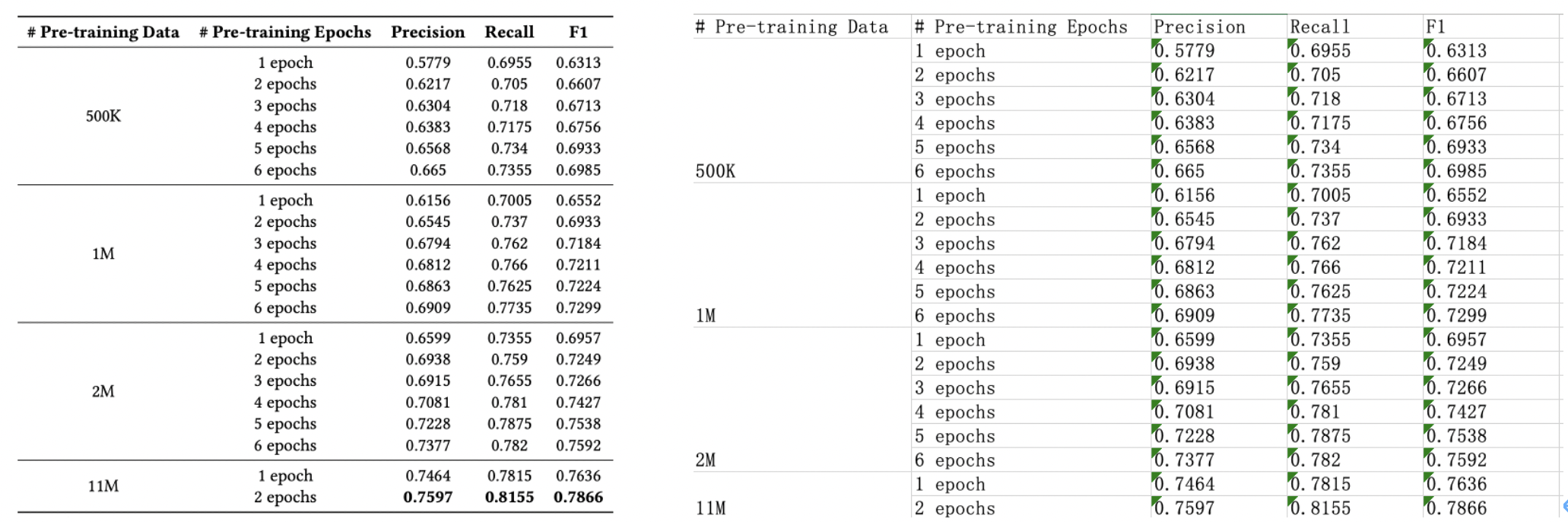
"**Predict-train model layer**,base on PP-OCR and PP-Structure solution that PaddleOCR develop and open source PP series models apply to industry practice,include common、light、multi-language text detection and recognition model and complex document analysis models.All of PPseries models already done by deep optimize on the original which make peforamce and precision reach to industry level, the developer can direct apply to business also it can using business data doing simply fineturn, that easy make \"usefully model\" by itself.\r\n",
|
||||
"\r\n",
|
||||
"**Industrial deployment layer**,the PaddleOCR provide base on Paddle Inference's server side predict solution ,Base on Paddle Serving deployment solution,meanwhile provide PaddleSlim's model compress solution that can compress mode to small. Above deploy mode is throught train to inferenceinference under one circle that is ensure developer deploy mode is effective and stable.\r\n",
|
||||
"\r\n",
|
||||
"**Data tools layer**,PaddleOCR provide semi-auto data mark tools(PPOCRLabel) and data merge(Style-Text) that is support developer easy for make traing dataset and mark tags. The PPOCRLabel is firstly open source semi-auto OCR data mark tools which is resolve huge workload、 duplicate works 、human data mark need take long time and costs issues, The built-in PP-OCR model implements pre-marks+ human verfiy's mode that is improve data mark efficient,reduce human cost.The data merge tools Style-Text is resolve lack actualy data problem, In tradition merge methods can not merge text styles(Font、color、gaps、background) issues. It just a litter target images that can be make a lot similarity images.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"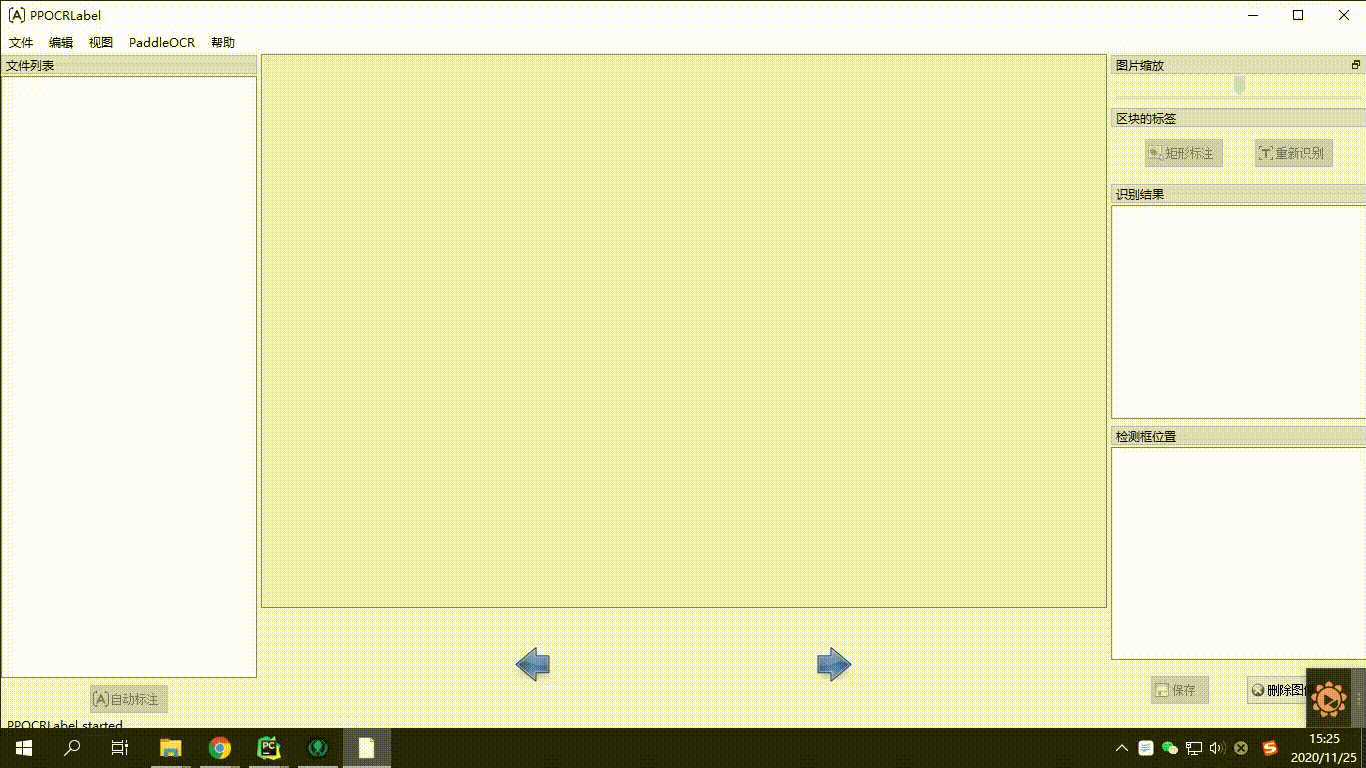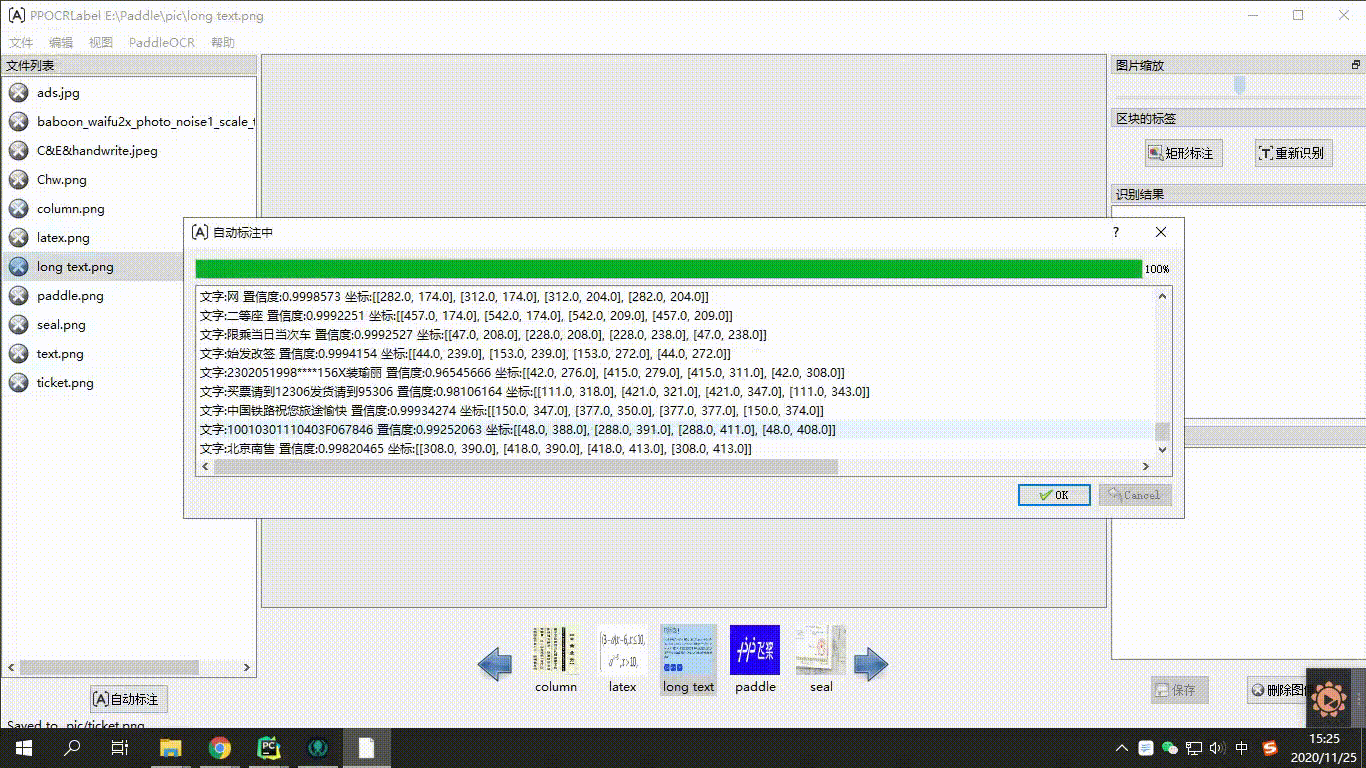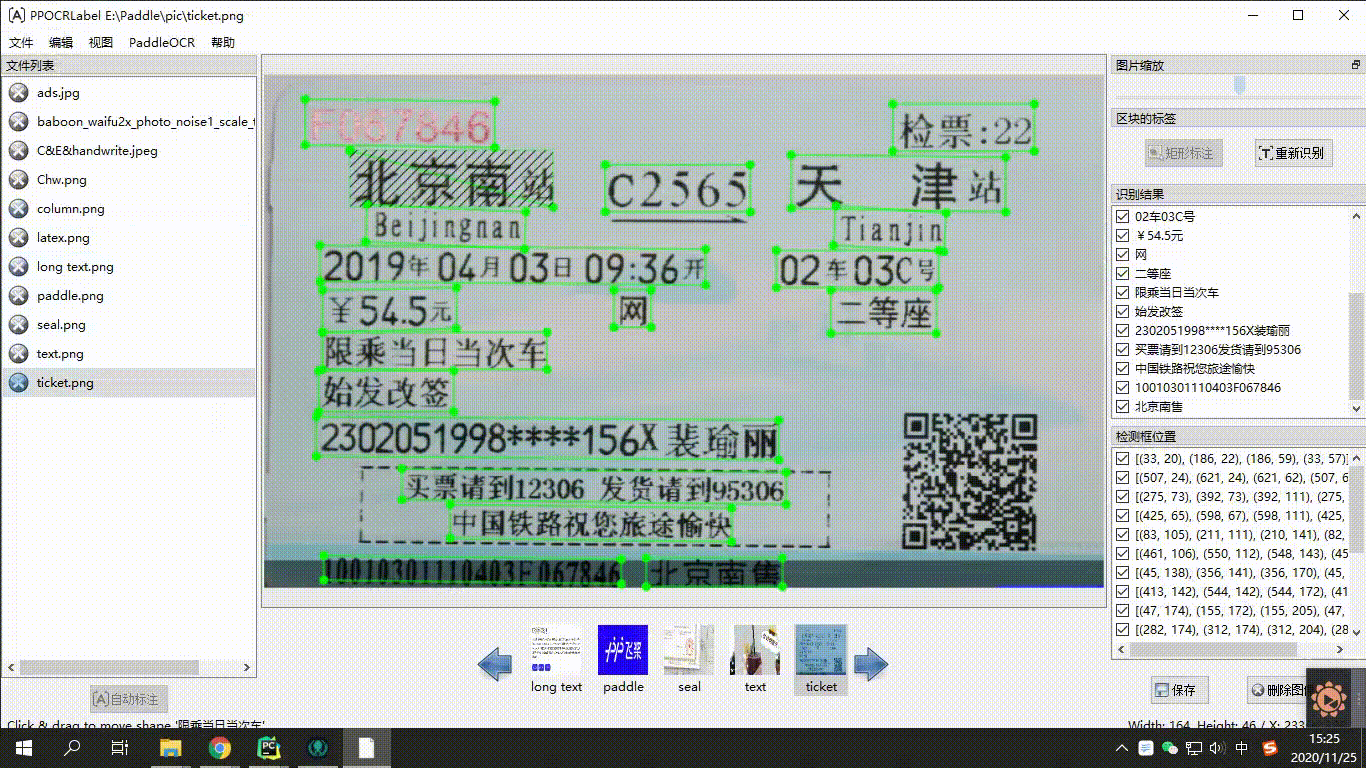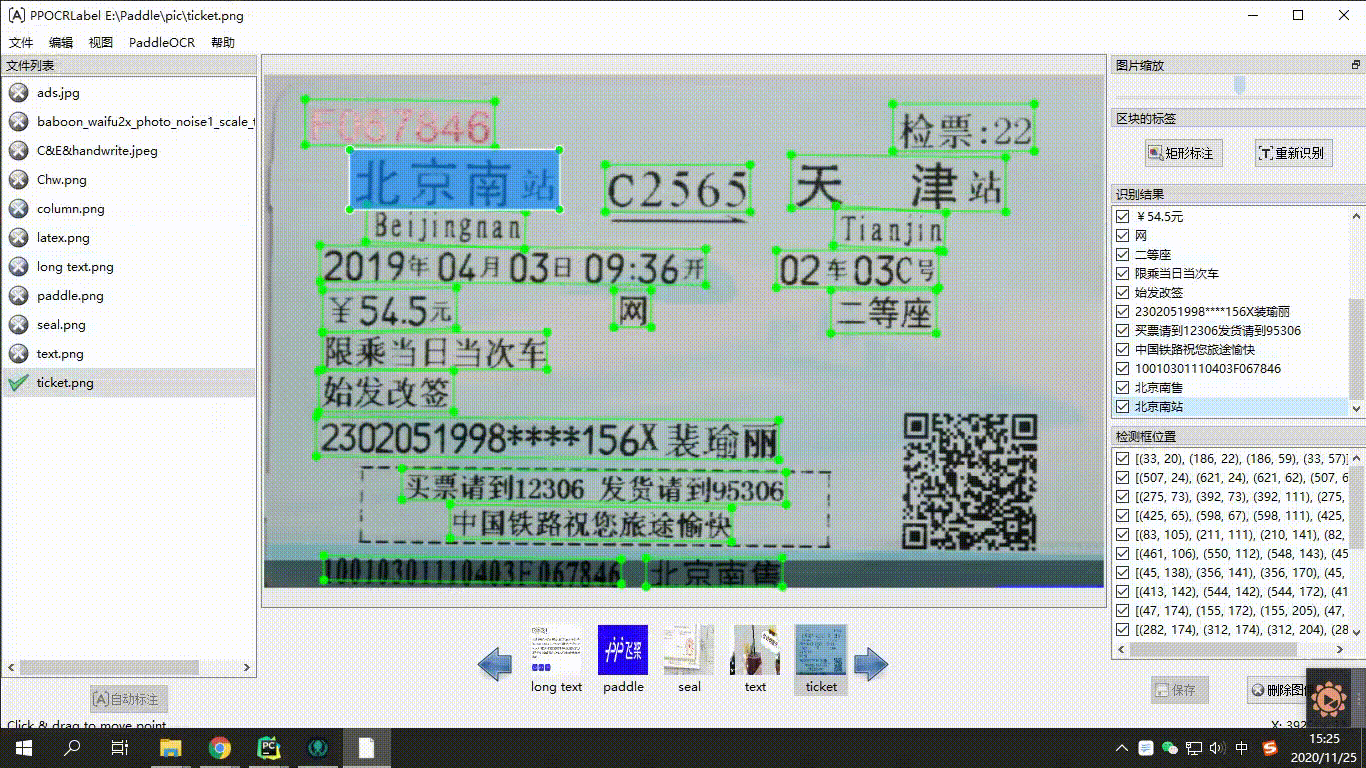\r\n",
|
||||
"<center>Figure19 PPOCRLabel schematic diagram </center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure20 Sample of Style-Text merge result </center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"\r\n",
|
||||
"### 3.2.1 PP-OCR vs PP-Structrue\r\n",
|
||||
"\r\n",
|
||||
"PP series models is Paddle vision development suites that is according to industrial requirements that is need blance with speed and precision. The PaddleOCR of text detection and recognition tasks include PP series models and object-oriented document analysis's PP-Structure's series models.\r\n",
|
||||
"\r\n",
|
||||
"**(1)PP-OCR Chinese and English models**\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure21 Sample PP-OCR Chinese and English model result</center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"PP-OCR Chinese and English mode using 2 phases OCR algorithm which is detection model+ recognition model the algorithm logic as below:\r\n",
|
||||
"\r\n",
|
||||
"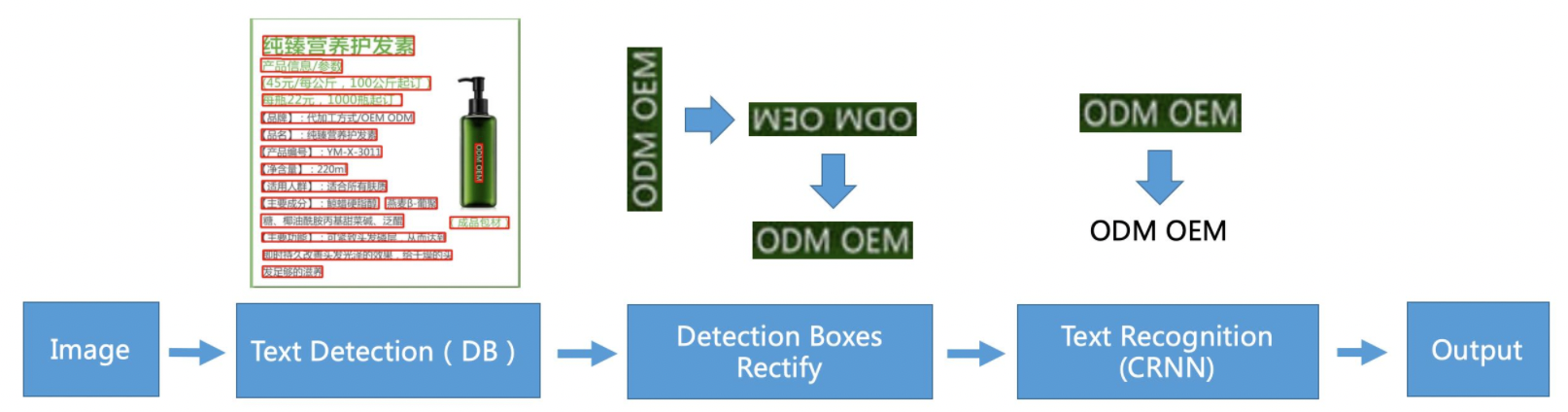\r\n",
|
||||
"<center>Figure22 PP-OCR system pipeline diagram</center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"It to be see,That ipout and putput the PP-OCR core framework including 3 modules that is text detection、correct text detection box、text recognition. \r\n",
|
||||
"\r\n",
|
||||
"- Text Detection module:the keynotes is that base on [DB](https://arxiv.org/abs/1911.08947) detection train's text detection models, for find out text area which in the images;\r\n",
|
||||
"- Correct text detection box module :which is input check box that already detection text area,In this phase that will make 4 points for correct text area for easy for next step text recognition,On the other hand that is text rotate check and refine,eg check text line is reversal then will doing rotate, this function implement by train text rotate classification;\r\n",
|
||||
"- Text Recognition module:finally doing Text Recognition when finish check and refine text area which will get each text box's contents,PP-OCR using classical text recognition algorithm[CRNN](https://arxiv.org/abs/1507.05717)。\r\n",
|
||||
"\r\n",
|
||||
"PaddleOCR has done PP-OCR[23] and PP-OCRv2[24] models.\r\n",
|
||||
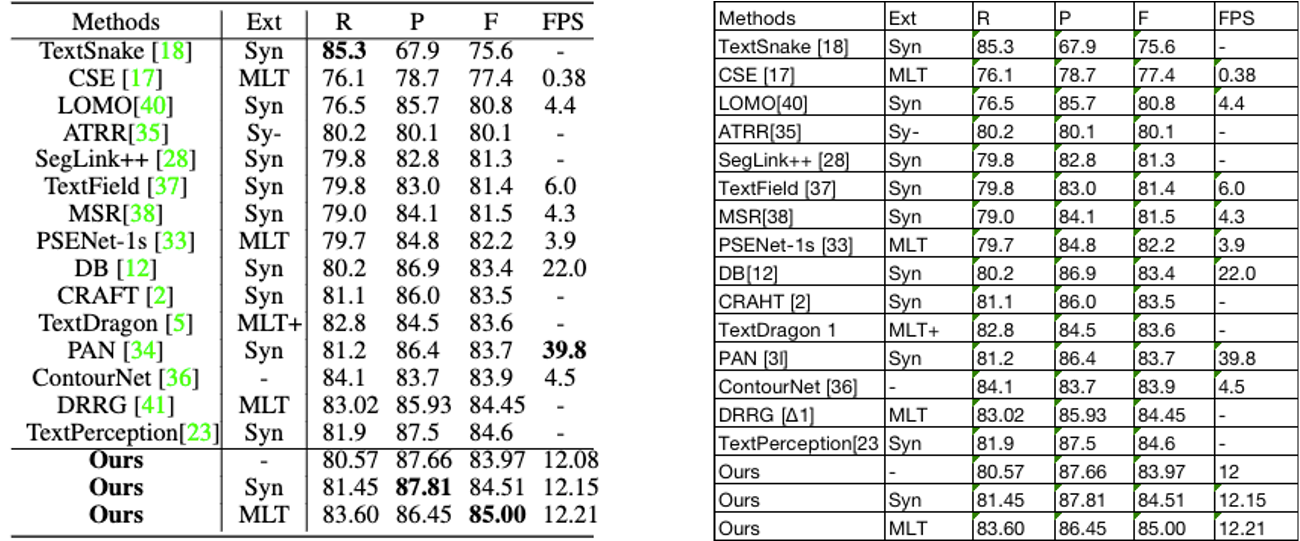
"PP-OCR models has mobile version (light version) and server version(common version),The mobile version major apply to light backbone network MobileNetV3 for refine, after refine (text detection + text classification model + recognition model) size only 8.1M ,CPU predict time consuming is 350ms for each image,T4 GPU is 110ms,After cropping and tunning that size will reduce to 3.5M that keep precision is same which means easy for end side deploy,At Snapdragon 855 test result that predict time consuming is 260ms.For more eval data please reference [benchmark](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.2/doc/doc_ch/benchmark.md).\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"The PP-OCRv2 keep PP-OCR whole frameworks, mainly change is done policy turnning for performace.The improve include 3 sides:\r\n",
|
||||
"\r\n",
|
||||
"- At model pefromance,Compare with PP-OCR mobile up 7%; \r\n",
|
||||
"- At model respone,Compare with PP-OCR server up 220%;\r\n",
|
||||
"- At model size ,totally 11.6M,that easy for deploy at server and mobile side.\r\n",
|
||||
"\r\n",
|
||||
"PP-OCR and PP-OCRv2 detail content will put on Chapter 4.\r\n",
|
||||
"\r\n",
|
||||
"Beside Chinese English model,PaddleOCR also base on difference train dataset and open source english numbers model、multi language recognition model, as those models is lightly type mode that is suitable for difference language scene.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure23 PP-OCR English number models and multi-language models recognition effect diagram</center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"\r\n",
|
||||
"**(2)PP-Structure document analysis models**\r\n",
|
||||
"PP-Structure support 3 kinds subtask that is layout analysis、table recognition、DocVQA.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"PP-Structure core function list:\r\n",
|
||||
"- Support image type document layout analysis, that can recognition words、title、table、picture and list 5 class area(with Layout-Parse use)\r\n",
|
||||
"- Support table area structure analysis and ouput to Excel\r\n",
|
||||
"- Support python whl package and command line 2 modes that easy use\r\n",
|
||||
"- Support layout analysis and table structure tasks user-difine training\r\n",
|
||||
"- Support VQA-SER and RE\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure24 PP-Structure system diagram(only layout analysis and table recognition )</center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"PP-Structure's more information at Chapter 6.\r\n",
|
||||
"\r\n",
|
||||
"### 3.2.2 Industrial deployment solutions\r\n",
|
||||
"Paddle support full circle、full scene inference deploy, the model source from 3 chanels,Firstly using PaddlePaddle API built it,\r\n",
|
||||
"Second that base on PaddlePaddle suites.That is provide rich-model repository、easy use API,that is out-of-the-box functionality,include vision model library PaddleCV 、Smart voices PaddleSpeech and NLP library PaddleNLP etc,third is from 3 partly framework(PyTorh、ONNX、TensorFlow etcs) that is using X2Paddle tool.\r\n",
|
||||
"\r\n",
|
||||
"Paddle mode can be choice PaddleSlim for model compress、quantification and distillation support 5 kinds deploy solution that is Serving's Paddle Serving、Server/Cloud side Paddle Inference、mobile/edge side Paddle lite、web side Paddle.JS ,About Paddle did not support hardware eg MCU、Horizon、Corerain etc China Chips, it can support ONNX thrid-party frameworks by Paddle2ONNX.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"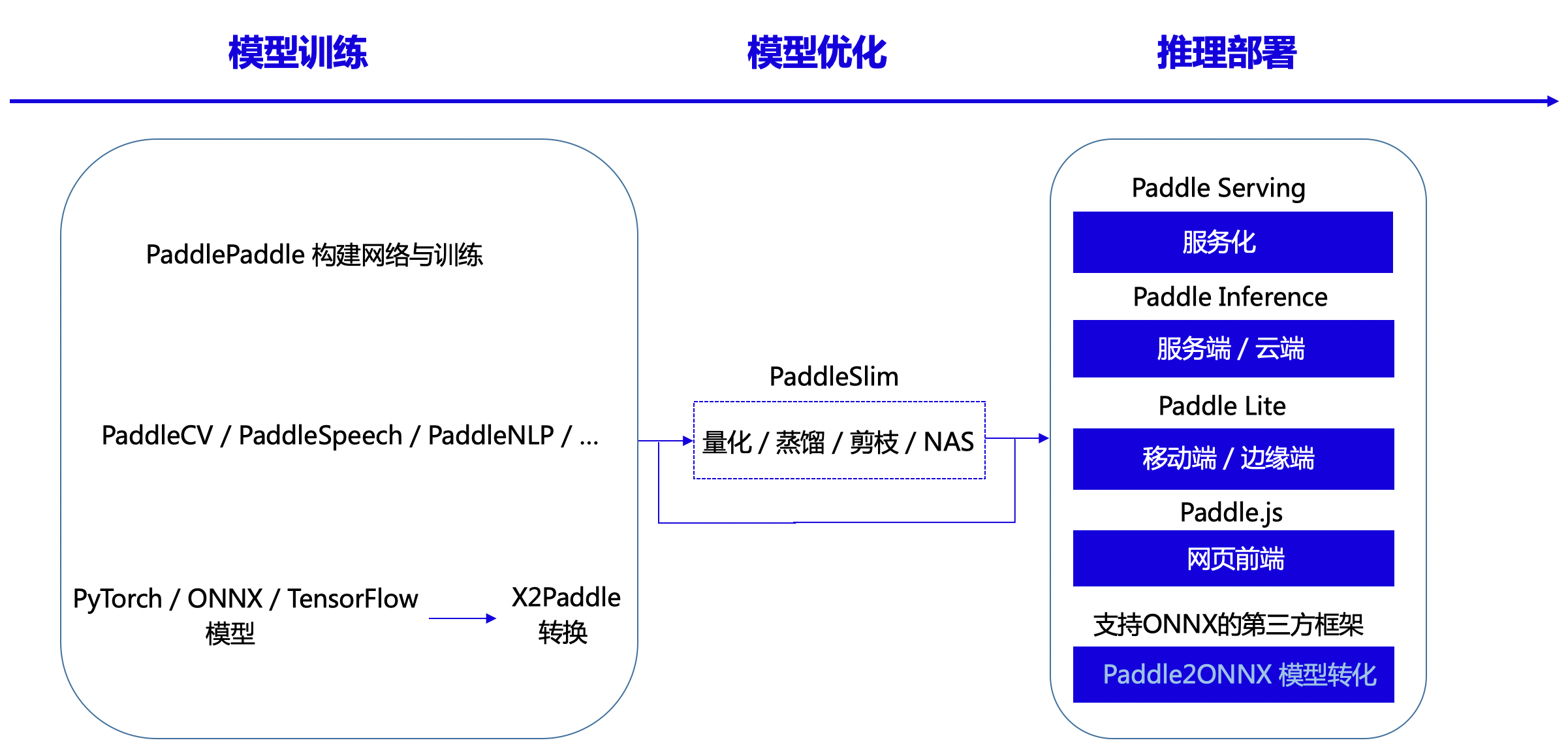\r\n",
|
||||
"<center>Figure25 Paddle support deploy modes</center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"Paddle Inference support servver and cloud deploy that is high performance and common, The focus differencec platform and difference application requirement that make deep match and turnning,Paddle Inference is original Paddle inference library that ensure the model as train as use it at server side, quickly deploy that will fine for deploy complex model that is using multi-language.The hardware cover to x86 CPU、Nvidia GPU、 Baidu Kunlun、Huawei ascent etc AI accelerator.\r\n",
|
||||
"\r\n",
|
||||
"Paddle Lite is end side inference that is lightly and high peformance features, base on side's devicecs and applicaction needs doing deep match and turnning.Currently support Android、IOS、embedded-Linux device、MacOS,hardware cover to ARM CPU和GPU、X86 CPU and Baidu Kunlun、Huawei ascent etc.\r\n",
|
||||
"\r\n",
|
||||
"Paddle Serving is high performance service framework that is support users rapid deploy models to cloud serving.Currently Paddle Serving support user_defined preprocessing and postprocessing 、merge model、mode hot loading updating、multi-machine、card distributed inference 、K8S deploy、safely getway and mode encryption 、support multi-language client access,Paddle Serving also include 40+ models deploy samples,which help users quickly do that. \r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure26 Paddle support deploy models</center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"\r\n",
|
||||
"Above deploy solutions will introduce at Chapter 5 PP-OCRV2 model. "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"source": [
|
||||
"# 4. Conclusion\r\n",
|
||||
"\r\n",
|
||||
"In this section that introduce OCR technology's applicaction scene and leading algorithm and alalysis OCR application facing difficult points and 3 challenge on industry practice.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"This book follow-up section list as below:\r\n",
|
||||
"\r\n",
|
||||
"* Chapter 2,3 Introduce Text detection 、recognition and practice;\r\n",
|
||||
"* Chapter 4 Introduce PP-OCR Optimization Policy; \r\n",
|
||||
"* Chapter 5 Predict deploy practice; \r\n",
|
||||
"* Chapter 6 Introducec structure document; \r\n",
|
||||
"* Chapter 7 Introduce End to End、data pre-processing、data merge etc OCR algorithm; \r\n",
|
||||
"* Chapter 8 Introduce OCR dataset and data building tools.\r\n",
|
||||
"\r\n",
|
||||
"# Reference\r\n",
|
||||
"\r\n",
|
||||
"[1] Liao, Minghui, et al. \"Textboxes: A fast text detector with a single deep neural network.\" Thirty-first AAAI conference on artificial intelligence. 2017.\r\n",
|
||||
"\r\n",
|
||||
"[2] Liu W, Anguelov D, Erhan D, et al. Ssd: Single shot multibox detector[C]//European conference on computer vision. Springer, Cham, 2016: 21-37.\r\n",
|
||||
"\r\n",
|
||||
"[3] Tian, Zhi, et al. \"Detecting text in natural image with connectionist text proposal network.\" European conference on computer vision. Springer, Cham, 2016.\r\n",
|
||||
"\r\n",
|
||||
"[4] Ren S, He K, Girshick R, et al. Faster r-cnn: Towards real-time object detection with region proposal networks[J]. Advances in neural information processing systems, 2015, 28: 91-99.\r\n",
|
||||
"\r\n",
|
||||
"[5] Zhou, Xinyu, et al. \"East: an efficient and accurate scene text detector.\" Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2017.\r\n",
|
||||
"\r\n",
|
||||
"[6] Wang, Wenhai, et al. \"Shape robust text detection with progressive scale expansion network.\" Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.\r\n",
|
||||
"\r\n",
|
||||
"[7] Liao, Minghui, et al. \"Real-time scene text detection with differentiable binarization.\" Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 34. No. 07. 2020.\r\n",
|
||||
"\r\n",
|
||||
"[8] Deng, Dan, et al. \"Pixellink: Detecting scene text via instance segmentation.\" Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 32. No. 1. 2018.\r\n",
|
||||
"\r\n",
|
||||
"[9] He K, Gkioxari G, Dollár P, et al. Mask r-cnn[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2961-2969.\r\n",
|
||||
"\r\n",
|
||||
"[10] Wang P, Zhang C, Qi F, et al. A single-shot arbitrarily-shaped text detector based on context attended multi-task \r\n",
|
||||
"learning[C]//Proceedings of the 27th ACM international conference on multimedia. 2019: 1277-1285.\r\n",
|
||||
"\r\n",
|
||||
"[11] Shi, B., Bai, X., & Yao, C. (2016). An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE transactions on pattern analysis and machine intelligence, 39(11), 2298-2304.\r\n",
|
||||
"\r\n",
|
||||
"[12] Star-Net Max Jaderberg, Karen Simonyan, Andrew Zisserman, et al. Spa- tial transformer networks. In Advances in neural information processing systems, pages 2017–2025, 2015.\r\n",
|
||||
"\r\n",
|
||||
"[13] Shi, B., Wang, X., Lyu, P., Yao, C., & Bai, X. (2016). Robust scene text recognition with automatic rectification. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4168-4176).\r\n",
|
||||
"\r\n",
|
||||
"[14] Sheng, F., Chen, Z., & Xu, B. (2019, September). NRTR: A no-recurrence sequence-to-sequence model for scene text recognition. In 2019 International Conference on Document Analysis and Recognition (ICDAR) (pp. 781-786). IEEE.\r\n",
|
||||
"\r\n",
|
||||
"[15] Lyu P, Liao M, Yao C, et al. Mask textspotter: An end-to-end trainable neural network for spotting text with arbitrary shapes[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 67-83.\r\n",
|
||||
"\r\n",
|
||||
"[16] Soto C, Yoo S. Visual detection with context for document layout analysis[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019: 3464-3470.\r\n",
|
||||
"\r\n",
|
||||
"[17] Sarkar M, Aggarwal M, Jain A, et al. Document Structure Extraction using Prior based High Resolution Hierarchical Semantic Segmentation[C]//European Conference on Computer Vision. Springer, Cham, 2020: 649-666.\r\n",
|
||||
"\r\n",
|
||||
"[18] Kieninger T, Dengel A. A paper-to-HTML table converting system[C]//Proceedings of document analysis systems (DAS). 1998, 98: 356-365.\r\n",
|
||||
"\r\n",
|
||||
"[19] Siddiqui S A, Fateh I A, Rizvi S T R, et al. Deeptabstr: Deep learning based table structure recognition[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019: 1403-1409.\r\n",
|
||||
"\r\n",
|
||||
"[20] Raja S, Mondal A, Jawahar C V. Table structure recognition using top-down and bottom-up cues[C]//European Conference on Computer Vision. Springer, Cham, 2020: 70-86.\r\n",
|
||||
"\r\n",
|
||||
"[21] Xue W, Yu B, Wang W, et al. TGRNet: A Table Graph Reconstruction Network for Table Structure Recognition[J]. arXiv preprint arXiv:2106.10598, 2021.\r\n",
|
||||
"\r\n",
|
||||
"[22] Ye J, Qi X, He Y, et al. PingAn-VCGroup's Solution for ICDAR 2021 Competition on Scientific Literature Parsing Task B: Table Recognition to HTML[J]. arXiv preprint arXiv:2105.01848, 2021.\r\n",
|
||||
"\r\n",
|
||||
"[23] Du Y, Li C, Guo R, et al. PP-OCR: A practical ultra lightweight OCR system[J]. arXiv preprint arXiv:2009.09941, 2020.\r\n",
|
||||
"\r\n",
|
||||
"[24] Du Y, Li C, Guo R, et al. PP-OCRv2: Bag of Tricks for Ultra Lightweight OCR System[J]. arXiv preprint arXiv:2109.03144, 2021.\r\n",
|
||||
"\r\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3.8.5 64-bit (conda)",
|
||||
"name": "python385jvsc74a57bd0e746eafcc9c3755c618fd70b7289e2c77c6dfaa86036ed9f41128bb78d1ac1c4"
|
||||
},
|
||||
"language_info": {
|
||||
"name": "python",
|
||||
"version": ""
|
||||
},
|
||||
"orig_nbformat": 3
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 1
|
||||
}
|
||||
File diff suppressed because one or more lines are too long
|
|
@ -0,0 +1,490 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"source": [
|
||||
"\r\n",
|
||||
"*Note:Above picutres source from Internet *\r\n",
|
||||
"\r\n",
|
||||
"# 1. OCR Background\r\n",
|
||||
"## 1.1 OCR Application Scenario\r\n",
|
||||
"\r\n",
|
||||
"* **<font color=red>What is OCR</font>**\r\n",
|
||||
"\r\n",
|
||||
"OCR(Optical Character Recognition)is one of application branch at computer vision. The OCR application scope is tradition defintion is object-oriented scan documents,Now OCR regular application area is STR(Scene Text Recognition) that is object-oriented \r\n",
|
||||
"natural scenario, such as below pictures that is natural visiable words.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure1 Document scenario word recognition VS. Natural scenario word recognition </center> \r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"\r\n",
|
||||
"* **<font color=red>What is OCR application OCR scenario?</font>**\r\n",
|
||||
"\r\n",
|
||||
"OCR technology has rich application scenario. one of classics OCR application scenario is vertical-oriented of structuring text recognition, such as License plate recognition、bank card infromation recognition、ID card information recognition、ticket information recognition etc. These vertical-oriented OCR application has common features is fixed-fomat, that means applition OCR technology will automatic those jobs ,that will reduce human resource cost and improve work efficiency. \r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"Recentlly OCR application focus at vertical-oriented of structuring text recognition\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure2 OCR application scenario</center>\r\n",
|
||||
"\r\n",
|
||||
"Beside of vertical-oriented of structuring text recognition. The general OCR technology also has wide range applicaction mode and usually combine with other area technology for handle multi-mode task, such video scenario using OCR technology doing Automatic subtitle translation、security monitoring etc, or combine with video frame features for understanding video content、 searching video frame. \r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure3 General OCR of multi-mode task</center>\r\n",
|
||||
"\r\n",
|
||||
"## 1.2 OCR technology challenge\r\n",
|
||||
"OCR technology challenge from algorithm layer and application layer.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"* **<font color=red>Algorithm layer</font>**\r\n",
|
||||
"\r\n",
|
||||
"OCR has rich application scenario, that means will exists a lot of diffficutly technology point. This article put 8 kinds technology questions:\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>图4 OCR Algorithm layer technical point</center>\r\n",
|
||||
"\r\n",
|
||||
"The Text detection and text recognition's technical challenge from those questions. It can be understanding that us from nutural scenario, Currently academic community is focus on OCR \r\n",
|
||||
"*Note:Above picutres source from Internet *\r\n",
|
||||
"\r\n",
|
||||
"# 1. OCR Background\r\n",
|
||||
"## 1.1 OCR Application Scenario\r\n",
|
||||
"\r\n",
|
||||
"* **<font color=red>What is OCR</font>**\r\n",
|
||||
"\r\n",
|
||||
"OCR(Optical Character Recognition)is one of application branch at computer vision. The OCR application scope is tradition defintion is object-oriented scan documents,Now OCR regular application area is STR(Scene Text Recognition) that is object-oriented \r\n",
|
||||
"natural scenario, such as below pictures that is natural visiable words.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure1 Document scenario word recognition VS. Natural scenario word recognition </center> \r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"\r\n",
|
||||
"* **<font color=red>What is OCR application OCR scenario?</font>**\r\n",
|
||||
"\r\n",
|
||||
"OCR technology has rich application scenario. one of classics OCR application scenario is vertical-oriented of structuring text recognition, such as License plate recognition、bank card infromation recognition、ID card information recognition、ticket information recognition etc. These vertical-oriented OCR application has common features is fixed-fomat, that means applition OCR technology will automatic those jobs ,that will reduce human resource cost and improve work efficiency. \r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"Recentlly OCR application focus at vertical-oriented of structuring text recognition\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure2 OCR application scenario</center>\r\n",
|
||||
"\r\n",
|
||||
"Beside of vertical-oriented of structuring text recognition. The general OCR technology also has wide range applicaction mode and usually combine with other area technology for handle multi-mode task, such video scenario using OCR technology doing Automatic subtitle translation、security monitoring etc, or combine with video frame features for understanding video content、 searching video frame. \r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure3 General OCR of multi-mode task</center>\r\n",
|
||||
"\r\n",
|
||||
"## 1.2 OCR technology challenge\r\n",
|
||||
"OCR technology challenge from algorithm layer and application layer.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"* **<font color=red>c</font>**\r\n",
|
||||
"\r\n",
|
||||
"OCR has rich application scenario, that means will exists a lot of diffficutly technology point. This article put 8 kinds technology questions:\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure4 OCR Algorithm layer technical point</center>\r\n",
|
||||
"\r\n",
|
||||
"The Text detection and text recognition's technical challenge from those questions. It can be understanding that us from nutural scenario, Currently academic community is focus on OCR nutural scenario.As for the above problems the recognition will difficult rather than detection.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"* **<font color=red>Application layer</font>**\r\n",
|
||||
"In practically OCR regrular application mode besdide of abolve chapter conclusion algorithm layer problem list such Affine transformation, scale problems, insufficient lighting, fuzzy shooting etc.The OCR application layer also exist 2 problems:\r\n",
|
||||
"1. **OCR real-handle at Big-data** Usually OCR application need facing handle huge data,We need data can be real-time process,The mode feedback response time is big problem.\r\n",
|
||||
"2. **The End-side applicaion need OCR mode is lightly, recognition sppeed is on time** The OCR application deploy nned take on mobile side or embedded hardware, In usually there are 2 modes End-side OCR deploy mode: upload to server vs. End-side direct recognition, That consider upload server handle needs network traffic,low real-time respone ,server-side workload will high when \r\n",
|
||||
"concurrent requests too large and data security problems.So we proposals at End-sides deploy and handle OCR recognition, also it will facing storge space and computation resoure limit that will the OCR mode size and predict speed has constraint. \r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure5 OCR application layer points</center>\r\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"source": [
|
||||
"# 2. OCR frontier algorithm\r\n",
|
||||
"\r\n",
|
||||
"Although OCR is a relative to the specific's jobs, howerver that involve with multi-sides technique include Text detection、Text recognition、End-to-End text recognition、Document analysis etc. In academic community side related OCR technique research result is upstrems.As below will introduce some critical points about OCR. \r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"## 2.1 Text detection\r\n",
|
||||
"\r\n",
|
||||
"Text detection is focus on locate with input images's text area.In recentlly years about text detection reearch is full rich at In academic community, one roadmap text detection is one of target detection instance,that base on improve target detection algorithm\r\n",
|
||||
"for text detection,such as TextBoxes[1] is base on one-phase target detection SSD[2] algorithm, resize target text box for long-text line size,CTPN[3] is base on Faster RCNN[4] is from improve structured.Howerver text detection not same as target detection, such text is width and height usually too large,it seems like \"bar sharp\",may be text line gaps is closely,curve texts etc. so it has raise specials algorithm for text detection, such as EAST[5]、PSENet[6]、DBNet[7] etc.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center><img src=\"https://ai-studio-static-online.cdn.bcebos.com/548b50212935402abb2e671c158c204737c2c64b9464442a8f65192c8a31b44d\" width=\"500\"></center>\r\n",
|
||||
"<center>Figure6 Sample of text detection</center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"Currently more popularly text detection algorithm is **Base on regression**和**Base on split**, some of algorithm is combine 2 kinds logic. Base on regression is reference object detection algorithm, that setup anchor text box or direct pix regression,this \r\n",
|
||||
"method is fine for regular text detection, but non-regular text detection is not fine,eg CTPN[3] at horizontal line text detection performnce is fine,but not good with incline 、curve text detection.SegLink[8] is good with long text line mode,but low performance with sparse text; Base on split algorithm import Mask-RCNN[9], those algorithms facing all kind of sharps text detection performance will up to better level, but one of weakness is so complex which cause response performance problems and it not resolve \r\n",
|
||||
"overlap text detection issues.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center><img src=\"https://ai-studio-static-online.cdn.bcebos.com/4f4ea65578384900909efff93d0b7386e86ece144d8c4677b7bc94b4f0337cfb\" width=\"800\"></center>\r\n",
|
||||
"<center>Figure7 Overview of text detection algorithm</center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"\r\n",
|
||||
"||\r\n",
|
||||
"|---|---|---|\r\n",
|
||||
"<center>Figure8 (Left)Base on regression CTPN[3] optimize anchor (Middle)Base on split DB[7] optimize result (Right)Regression+Split SAST[10]</center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"About text detection detail description will introduce at chapter 2\r\n",
|
||||
"\r\n",
|
||||
"## 2.2 Text Recognition\r\n",
|
||||
"Text Recognition's main target is identify image text content, In generally Text Recognition is obtain images text area contents that from text detection result. According to Text Recognition methods that 2 class on that **Regular Text Recognition** and **Non-Regular Text Recognition**.Regular Text Recognition is print font、scan font,The text nera with horizontal line; Non-Regular Text Recognition usually position not near with horizontal line,that exist curve、mask、indistinct etc issues. Non-Regular Text Recognition has a big challenging, also is main OCR research area. \r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure9 (Left)Regular Text Recognition VS. (Right)Non-Regular Text Recognition</center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"\r\n",
|
||||
"There are CTC and Sequence2Sequence kinds for Regular Text Recognition that base on ecoding mode. That is deep learning sequence features convert to finally recognition output is diffenence. Base CTC algorithm represent is CRNN[11].\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure10 CTC Recognition algorithm VS. Attention Recognition algorithm</center>\r\n",
|
||||
"\r\n",
|
||||
"Non-Regular Text Recognition algorithm kinds is richer. Like STAR-Net[12] is addition TPS correction module that convert Non-Regular to Regular for Text Recognition; RARE[13] is Attention roadmap that enhance sequences attention; Base on split mode that split text line for each chars and compare with whole text line doing recognition, that is identify single chars is easy;\r\n",
|
||||
"Recentlly Transfomer[14] is quickly growing and obtain valid check at all kinds tasks, that is make some base on Transformer Text Recognition algorithm,This method using transformer structure for resolve CNN problem at long dependency mode building.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure11 Base on Split mode Text Recognition algorithm[15]</center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"\r\n",
|
||||
"Text Recognition deatil will put on chapter 3\r\n",
|
||||
"\r\n",
|
||||
"## 2.3 Structure-Document Recognition\r\n",
|
||||
"\r\n",
|
||||
"In tradition that OCR can resolve text detection and recognition request, but in OCR practical that need data is structure, eg ID card、invoice information extract,Table structure recognition,express document、contract content compare、insurance document information compare etc. The OCR result + after process is commonly structure solution,but the process logic is complex, and after process part need detail design, generalization performance is low. Now OCR is in mature period,that is structure information extract request is usually that is Layout analysis、 Table Recognition、Key Information Extraction etc smart document analysis technical is become more popular and focus.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"* **Layout Analysis**\r\n",
|
||||
"Layout Analysis is focus on document image content classification.The classification is pure-text、title、table、image etc.Usually that will make some layout tags for detection and recognition in documents,eg Soto Carlos[16] apply on target detection that base on\r\n",
|
||||
"Faster R-CNN,combine with content information and using documents posisition for improve text detection performance; Sarkar Mausoom[17] et al. proposed a prior-based segmentation mechanism that train document split mode under high resolution images which is resolve difficult on split and merge issue on narrow-resize orign-images that is dense tags. \r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure12 Layout Analysis Diagram</center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"\r\n",
|
||||
"* **Table Recognition**\r\n",
|
||||
"Table Recognition is recognition and convert document's table to Excel.The text image table is many kinds,eg row-col merge,various cells type, Beside those also document layout and photo light is rise huge challenge. These challenge cause Table Recognition is difficut point on document understand area. \r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure13 Table Recognition Diagram </center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"There are many roadmap on Table Recognition,early is base on traditional algorithm for heuristic rules,Such as T-RECT algorithm proposed by Kieninger et al. [18],Usually is config rules for human,connected domain detection analysis and processing;Recently years that deep learning is popular that is appears base on CNN's Table Recognition methods, eg Siddiqui Shoaib Ahmed[19] propose base on DeepTabStR,Raja Sachin[20] propose TabStruct-Net;In addition Graph Neural Network is mature,some researchers try to Graph Neural Network apply on Table Recognition, base on Graph Neural Network area is re-building Graph works for Table Recognition,eg\r\n",
|
||||
"Xue Wenyuan[21] is propose TGRNet; End-to-End method direct using network understand table structure and show output HTML.Most End-to-End methods using Seq2Seq, eg Attention and Transformer such as TableMaster[22].\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure14 Table Recognition Method Diagram</center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"\r\n",
|
||||
"* **Key Information Extraction**\r\n",
|
||||
"Key Information Extraction is important tasks on Document VQA,that is Extract informtion from images, eg extract name and Id card No from ID cards, those information is fixed on special task and differcnce with difference tasks.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure15 DocVQA Diagram</center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"KIE 2 sub-tasks:\r\n",
|
||||
"\r\n",
|
||||
"- SER: Semantic Entity Recognition,that is text classification foe each detection text area.eg c name , ID card, from below image blank frame and red frame.\r\n",
|
||||
"- RE: Relation Extraction,that is text classification foe each detection text,eg identify question and answer.such as below red frame and blank frame is menas question and answer, yellow line means relation with question and answer. \r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure16 ser and re task</center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"In generally KIE is base on Named Entity Recognition,NER[4] for research, but this methos only using text information on image,lack of vision and structure information apply,which cause precision is low.Base on this,In recentlly year will take vision 、structure information to text information, According to mulit-mode information concepts that can get as below 4 roadmaps:\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"- Base on Grid \r\n",
|
||||
"- Base on Token\r\n",
|
||||
"- Base on GCN\r\n",
|
||||
"- Base on End to End\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"\r\n",
|
||||
"The document analysis will introduce at Chapter 6.\r\n",
|
||||
"\r\n",
|
||||
"## 2.4 Other Technique\r\n",
|
||||
"\r\n",
|
||||
"As above is introduce OCR area 3 critical technique:Text detection、Text Recognition、Structure-Document Recognition,other more OCR technique that include End-to-End text recognition、OCR image pre-process、OCR data merge etc, that reference Chapter 7 and Chapter 8.\r\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"source": [
|
||||
"# 3. OCR Industry Practice\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"> If you are Wang,How can do that? \r\n",
|
||||
"> 1. I can not,I did not it,I am leaving😭\r\n",
|
||||
"> 2. The suggest manager outsource or business solution ,That charge compay funds😊\r\n",
|
||||
"> 3. Find same case at Internet ,Oriented Github programing😏\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"\r\n",
|
||||
"Finally OCR technique will apply to Industry. Althought OCR technique academic's researchs is full,OCR technique business appliction is popular rather than others AI technique, howerver actually also exists some of trouble and issues. As below will take technique and Industry two views for anlysis.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"## 3.1 Industry Practice Keynotes\r\n",
|
||||
"\r\n",
|
||||
"In actually, developer will base on open source community start or push project, the deveoper apply open source mode will facing 3 difficult point:\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure17 3 difficult point on OCR Industry Practice</center>\r\n",
|
||||
"\r\n",
|
||||
"**1. Can not find、 Can not choice**\r\n",
|
||||
"The rich resources on open source community,but information dissymmetry which cause low efficiency support developer. One hand,open source community resource is too manys,the developer facing request,difficult with choice better project fron huge code repository.\r\n",
|
||||
"That means \"Can not find\" problem; other hand,at chcoice mode,Open English dataset index did not give direct reference on chinese environment, case by case check and confirm need take long time and humans and it not make sure this is best choice,that is \"Can not choice\".\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"**2. did not match Industry**\r\n",
|
||||
"Open source community always focus on performance tunning,eg academic paper's code open source or reproduction,In generally that is keen on at algorithm output performance, balance with mode size and speed is lack,but mode size and predict Time-consuming is criticacl index at industry.At serve-side and mobile-side,need recognize images is manys that means mode size need become lighting and precision index is better,predict respone is faster. GPU is too expensive,using CPU running is economics. Before satisfy business condition, the mode is light that means calculcation resource is small.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"**3. Difficult with Tuning and optimize 、Trouble with traing and deploy mode**\r\n",
|
||||
"That always can not meet take bussiness requirement by direct using open source code,Actually apply OCR will facing a lot of problems,personalized business requirement that means need take user-difined data set for re-training,Currently check open source project output result is high cost. In addition OCR apply scene is full, the application cover to server side and moblie devices,\r\n",
|
||||
"hardware environment is difference which means need support solution is totally. Unfortunately keen on algorithm and mode from open\r\n",
|
||||
"source community,a lack of predict parts supports that means the developer need consider algorithm and engineering apply OCR from paper to scene sites. \r\n",
|
||||
"\r\n",
|
||||
"## 3.2 Industrial OCR development Suites PaddleOCR\r\n",
|
||||
"OCR Industrial practice need total solution full all life circle for rapid research and develop speed, saving develop time. As other words that super-light mode and full life circle soulution special for limition at calculate 、storge space resouces's moblie 、embeding devices is necessary.\r\n",
|
||||
"\r\n",
|
||||
"In this background, Industrial grade OCR development suites [PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR) is appear.\r\n",
|
||||
"\r\n",
|
||||
"PaddleOCR's roadmap is from user images and requirerment that base on Paddle core framework which choice rich leading algorithm for apply to Industry's PP styles models and make to inference.PaddleOCR provvide manys predict deploys that is fine for differencce needs. \r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure18 PaddleOCR development Digram</center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"It can be see from digram that PaddleOCR base on Paddle core framework,There are rich-solutions at model algorithm、predict-train model、Industrial deployment and also provide data merge,semi-auto data marks which will satisfy end developer make data requeirements. \r\n",
|
||||
"\r\n",
|
||||
"**Model algorithm layer**,PaddleOCR has provide **Text detection and recognotion** and **structure document analysis** 2 kinds tasks's solution.At Text detection and recognotion side,PaddleOCR recurrence or open source 4 kinds Text detection algorithm、8 kinds Text recognotion algorithm、1 kind End-to-End Text detection algorithm,and base on those develop PP-OCR series common Text detection and recognotion solution; At structure document analysis side,PaddleOCR provvide layout analysis、Table recognotion、Key information Extraction、Named Entities etc, base on above foundation made PP-Structure document analysis solution. The refine algorithm can be satisfaction with developer at various of business requirements, the code framework also easy for developer doing compare with algorithm and performance.\r\n",
|
||||
"\r\n",
|
||||
"**Predict-train model layer**,base on PP-OCR and PP-Structure solution that PaddleOCR develop and open source PP series models apply to industry practice,include common、light、multi-language text detection and recognition model and complex document analysis models.All of PPseries models already done by deep optimize on the original which make peforamce and precision reach to industry level, the developer can direct apply to business also it can using business data doing simply fineturn, that easy make \"usefully model\" by itself.\r\n",
|
||||
"\r\n",
|
||||
"**Industrial deployment layer**,the PaddleOCR provide base on Paddle Inference's server side predict solution ,Base on Paddle Serving deployment solution,meanwhile provide PaddleSlim's model compress solution that can compress mode to small. Above deploy mode is throught train to inferenceinference under one circle that is ensure developer deploy mode is effective and stable.\r\n",
|
||||
"\r\n",
|
||||
"**Data tools layer**,PaddleOCR provide semi-auto data mark tools(PPOCRLabel) and data merge(Style-Text) that is support developer easy for make traing dataset and mark tags. The PPOCRLabel is firstly open source semi-auto OCR data mark tools which is resolve huge workload、 duplicate works 、human data mark need take long time and costs issues, The built-in PP-OCR model implements pre-marks+ human verfiy's mode that is improve data mark efficient,reduce human cost.The data merge tools Style-Text is resolve lack actualy data problem, In tradition merge methods can not merge text styles(Font、color、gaps、background) issues. It just a litter target images that can be make a lot similarity images.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure19 PPOCRLabel schematic diagram </center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure20 Sample of Style-Text merge result </center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"\r\n",
|
||||
"### 3.2.1 PP-OCR vs PP-Structrue\r\n",
|
||||
"\r\n",
|
||||
"PP series models is Paddle vision development suites that is according to industrial requirements that is need blance with speed and precision. The PaddleOCR of text detection and recognition tasks include PP series models and object-oriented document analysis's PP-Structure's series models.\r\n",
|
||||
"\r\n",
|
||||
"**(1)PP-OCR Chinese and English models**\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure21 Sample PP-OCR Chinese and English model result</center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"PP-OCR Chinese and English mode using 2 phases OCR algorithm which is detection model+ recognition model the algorithm logic as below:\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure22 PP-OCR system pipeline diagram</center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"It to be see,That ipout and putput the PP-OCR core framework including 3 modules that is text detection、correct text detection box、text recognition. \r\n",
|
||||
"\r\n",
|
||||
"- Text Detection module:the keynotes is that base on [DB](https://arxiv.org/abs/1911.08947) detection train's text detection models, for find out text area which in the images;\r\n",
|
||||
"- Correct text detection box module :which is input check box that already detection text area,In this phase that will make 4 points for correct text area for easy for next step text recognition,On the other hand that is text rotate check and refine,eg check text line is reversal then will doing rotate, this function implement by train text rotate classification;\r\n",
|
||||
"- Text Recognition module:finally doing Text Recognition when finish check and refine text area which will get each text box's contents,PP-OCR using classical text recognition algorithm[CRNN](https://arxiv.org/abs/1507.05717)。\r\n",
|
||||
"\r\n",
|
||||
"PaddleOCR has done PP-OCR[23] and PP-OCRv2[24] models.\r\n",
|
||||
"PP-OCR models has mobile version (light version) and server version(common version),The mobile version major apply to light backbone network MobileNetV3 for refine, after refine (text detection + text classification model + recognition model) size only 8.1M ,CPU predict time consuming is 350ms for each image,T4 GPU is 110ms,After cropping and tunning that size will reduce to 3.5M that keep precision is same which means easy for end side deploy,At Snapdragon 855 test result that predict time consuming is 260ms.For more eval data please reference [benchmark](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.2/doc/doc_ch/benchmark.md).\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"The PP-OCRv2 keep PP-OCR whole frameworks, mainly change is done policy turnning for performace.The improve include 3 sides:\r\n",
|
||||
"\r\n",
|
||||
"- At model pefromance,Compare with PP-OCR mobile up 7%; \r\n",
|
||||
"- At model respone,Compare with PP-OCR server up 220%;\r\n",
|
||||
"- At model size ,totally 11.6M,that easy for deploy at server and mobile side.\r\n",
|
||||
"\r\n",
|
||||
"PP-OCR and PP-OCRv2 detail content will put on Chapter 4.\r\n",
|
||||
"\r\n",
|
||||
"Beside Chinese English model,PaddleOCR also base on difference train dataset and open source english numbers model、multi language recognition model, as those models is lightly type mode that is suitable for difference language scene.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure23 PP-OCR English number models and multi-language models recognition effect diagram</center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"\r\n",
|
||||
"**(2)PP-Structure document analysis models**\r\n",
|
||||
"PP-Structure support 3 kinds subtask that is layout analysis、table recognition、DocVQA.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"PP-Structure core function list:\r\n",
|
||||
"- Support image type document layout analysis, that can recognition words、title、table、picture and list 5 class area(with Layout-Parse use)\r\n",
|
||||
"- Support table area structure analysis and ouput to Excel\r\n",
|
||||
"- Support python whl package and command line 2 modes that easy use\r\n",
|
||||
"- Support layout analysis and table structure tasks user-difine training\r\n",
|
||||
"- Support VQA-SER and RE\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure24 PP-Structure system diagram(only layout analysis and table recognition )</center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"PP-Structure's more information at Chapter 6.\r\n",
|
||||
"\r\n",
|
||||
"### 3.2.2 Industrial deployment solutions\r\n",
|
||||
"Paddle support full circle、full scene inference deploy, the model source from 3 chanels,Firstly using PaddlePaddle API built it,\r\n",
|
||||
"Second that base on PaddlePaddle suites.That is provide rich-model repository、easy use API,that is out-of-the-box functionality,include vision model library PaddleCV 、Smart voices PaddleSpeech and NLP library PaddleNLP etc,third is from 3 partly framework(PyTorh、ONNX、TensorFlow etcs) that is using X2Paddle tool.\r\n",
|
||||
"\r\n",
|
||||
"Paddle mode can be choice PaddleSlim for model compress、quantification and distillation support 5 kinds deploy solution that is Serving's Paddle Serving、Server/Cloud side Paddle Inference、mobile/edge side Paddle lite、web side Paddle.JS ,About Paddle did not support hardware eg MCU、Horizon、Corerain etc China Chips, it can support ONNX thrid-party frameworks by Paddle2ONNX.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure25 Paddle support deploy modes</center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"Paddle Inference support servver and cloud deploy that is high performance and common, The focus differencec platform and difference application requirement that make deep match and turnning,Paddle Inference is original Paddle inference library that ensure the model as train as use it at server side, quickly deploy that will fine for deploy complex model that is using multi-language.The hardware cover to x86 CPU、Nvidia GPU、 Baidu Kunlun、Huawei ascent etc AI accelerator.\r\n",
|
||||
"\r\n",
|
||||
"Paddle Lite is end side inference that is lightly and high peformance features, base on side's devicecs and applicaction needs doing deep match and turnning.Currently support Android、IOS、embedded-Linux device、MacOS,hardware cover to ARM CPU和GPU、X86 CPU and Baidu Kunlun、Huawei ascent etc.\r\n",
|
||||
"\r\n",
|
||||
"Paddle Serving is high performance service framework that is support users rapid deploy models to cloud serving.Currently Paddle Serving support user_defined preprocessing and postprocessing 、merge model、mode hot loading updating、multi-machine、card distributed inference 、K8S deploy、safely getway and mode encryption 、support multi-language client access,Paddle Serving also include 40+ models deploy samples,which help users quickly do that. \r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"<center>Figure26 Paddle support deploy models</center>\r\n",
|
||||
"\r\n",
|
||||
"<br>\r\n",
|
||||
"\r\n",
|
||||
"Above deploy solutions will introduce at Chapter 5 PP-OCRV2 model. "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"source": [
|
||||
"# 4. Conclusion\r\n",
|
||||
"\r\n",
|
||||
"In this section that introduce OCR technology's applicaction scene and leading algorithm and alalysis OCR application facing difficult points and 3 challenge on industry practice.\r\n",
|
||||
"\r\n",
|
||||
"\r\n",
|
||||
"This book follow-up section list as below:\r\n",
|
||||
"\r\n",
|
||||
"* Chapter 2,3 Introduce Text detection 、recognition and practice;\r\n",
|
||||
"* Chapter 4 Introduce PP-OCR Optimization Policy; \r\n",
|
||||
"* Chapter 5 Predict deploy practice; \r\n",
|
||||
"* Chapter 6 Introducec structure document; \r\n",
|
||||
"* Chapter 7 Introduce End to End、data pre-processing、data merge etc OCR algorithm; \r\n",
|
||||
"* Chapter 8 Introduce OCR dataset and data building tools.\r\n",
|
||||
"\r\n",
|
||||
"# Reference\r\n",
|
||||
"\r\n",
|
||||
"[1] Liao, Minghui, et al. \"Textboxes: A fast text detector with a single deep neural network.\" Thirty-first AAAI conference on artificial intelligence. 2017.\r\n",
|
||||
"\r\n",
|
||||
"[2] Liu W, Anguelov D, Erhan D, et al. Ssd: Single shot multibox detector[C]//European conference on computer vision. Springer, Cham, 2016: 21-37.\r\n",
|
||||
"\r\n",
|
||||
"[3] Tian, Zhi, et al. \"Detecting text in natural image with connectionist text proposal network.\" European conference on computer vision. Springer, Cham, 2016.\r\n",
|
||||
"\r\n",
|
||||
"[4] Ren S, He K, Girshick R, et al. Faster r-cnn: Towards real-time object detection with region proposal networks[J]. Advances in neural information processing systems, 2015, 28: 91-99.\r\n",
|
||||
"\r\n",
|
||||
"[5] Zhou, Xinyu, et al. \"East: an efficient and accurate scene text detector.\" Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2017.\r\n",
|
||||
"\r\n",
|
||||
"[6] Wang, Wenhai, et al. \"Shape robust text detection with progressive scale expansion network.\" Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.\r\n",
|
||||
"\r\n",
|
||||
"[7] Liao, Minghui, et al. \"Real-time scene text detection with differentiable binarization.\" Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 34. No. 07. 2020.\r\n",
|
||||
"\r\n",
|
||||
"[8] Deng, Dan, et al. \"Pixellink: Detecting scene text via instance segmentation.\" Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 32. No. 1. 2018.\r\n",
|
||||
"\r\n",
|
||||
"[9] He K, Gkioxari G, Dollár P, et al. Mask r-cnn[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2961-2969.\r\n",
|
||||
"\r\n",
|
||||
"[10] Wang P, Zhang C, Qi F, et al. A single-shot arbitrarily-shaped text detector based on context attended multi-task \r\n",
|
||||
"learning[C]//Proceedings of the 27th ACM international conference on multimedia. 2019: 1277-1285.\r\n",
|
||||
"\r\n",
|
||||
"[11] Shi, B., Bai, X., & Yao, C. (2016). An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE transactions on pattern analysis and machine intelligence, 39(11), 2298-2304.\r\n",
|
||||
"\r\n",
|
||||
"[12] Star-Net Max Jaderberg, Karen Simonyan, Andrew Zisserman, et al. Spa- tial transformer networks. In Advances in neural information processing systems, pages 2017–2025, 2015.\r\n",
|
||||
"\r\n",
|
||||
"[13] Shi, B., Wang, X., Lyu, P., Yao, C., & Bai, X. (2016). Robust scene text recognition with automatic rectification. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4168-4176).\r\n",
|
||||
"\r\n",
|
||||
"[14] Sheng, F., Chen, Z., & Xu, B. (2019, September). NRTR: A no-recurrence sequence-to-sequence model for scene text recognition. In 2019 International Conference on Document Analysis and Recognition (ICDAR) (pp. 781-786). IEEE.\r\n",
|
||||
"\r\n",
|
||||
"[15] Lyu P, Liao M, Yao C, et al. Mask textspotter: An end-to-end trainable neural network for spotting text with arbitrary shapes[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 67-83.\r\n",
|
||||
"\r\n",
|
||||
"[16] Soto C, Yoo S. Visual detection with context for document layout analysis[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019: 3464-3470.\r\n",
|
||||
"\r\n",
|
||||
"[17] Sarkar M, Aggarwal M, Jain A, et al. Document Structure Extraction using Prior based High Resolution Hierarchical Semantic Segmentation[C]//European Conference on Computer Vision. Springer, Cham, 2020: 649-666.\r\n",
|
||||
"\r\n",
|
||||
"[18] Kieninger T, Dengel A. A paper-to-HTML table converting system[C]//Proceedings of document analysis systems (DAS). 1998, 98: 356-365.\r\n",
|
||||
"\r\n",
|
||||
"[19] Siddiqui S A, Fateh I A, Rizvi S T R, et al. Deeptabstr: Deep learning based table structure recognition[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019: 1403-1409.\r\n",
|
||||
"\r\n",
|
||||
"[20] Raja S, Mondal A, Jawahar C V. Table structure recognition using top-down and bottom-up cues[C]//European Conference on Computer Vision. Springer, Cham, 2020: 70-86.\r\n",
|
||||
"\r\n",
|
||||
"[21] Xue W, Yu B, Wang W, et al. TGRNet: A Table Graph Reconstruction Network for Table Structure Recognition[J]. arXiv preprint arXiv:2106.10598, 2021.\r\n",
|
||||
"\r\n",
|
||||
"[22] Ye J, Qi X, He Y, et al. PingAn-VCGroup's Solution for ICDAR 2021 Competition on Scientific Literature Parsing Task B: Table Recognition to HTML[J]. arXiv preprint arXiv:2105.01848, 2021.\r\n",
|
||||
"\r\n",
|
||||
"[23] Du Y, Li C, Guo R, et al. PP-OCR: A practical ultra lightweight OCR system[J]. arXiv preprint arXiv:2009.09941, 2020.\r\n",
|
||||
"\r\n",
|
||||
"[24] Du Y, Li C, Guo R, et al. PP-OCRv2: Bag of Tricks for Ultra Lightweight OCR System[J]. arXiv preprint arXiv:2109.03144, 2021.\r\n",
|
||||
"\r\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3.8.5 64-bit (conda)",
|
||||
"name": "python385jvsc74a57bd0e746eafcc9c3755c618fd70b7289e2c77c6dfaa86036ed9f41128bb78d1ac1c4"
|
||||
},
|
||||
"language_info": {
|
||||
"name": "python",
|
||||
"version": ""
|
||||
},
|
||||
"orig_nbformat": 3
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 1
|
||||
}
|
||||
File diff suppressed because one or more lines are too long
|
|
@ -0,0 +1,80 @@
|
|||
---
|
||||
title: Key Information Extraction
|
||||
tags: [Import-62b7]
|
||||
created: '2022-01-04T02:35:39.839Z'
|
||||
modified: '2022-01-04T07:29:13.539Z'
|
||||
---
|
||||
|
||||
# Key Information Extraction
|
||||
|
||||
This section will introduce a quickly use and train keynotes extraction(KIE) using SDMGR in PaddleOCR.
|
||||
|
||||
SDMGR is a Key Information Extraction algorithm that is classifies each detected text area into predefined categories, such as order ID, invoice number, amount etc.
|
||||
|
||||
|
||||
|
||||
* [1. Quick Start](#1-----)
|
||||
* [2. Execution Training](#2-----)
|
||||
* [3. Execution Evaluation](#3-----)
|
||||
|
||||
<a name="1-----"></a>
|
||||
## 1. Quick Start
|
||||
|
||||
The Training and Evaluation data using wildreceipt dataset, It using as below commnad download:
|
||||
|
||||
```
|
||||
wget https://paddleocr.bj.bcebos.com/dygraph_v2.1/kie/wildreceipt.tar && tar xf wildreceipt.tar
|
||||
```
|
||||
|
||||
Evaluation:
|
||||
|
||||
```
|
||||
cd PaddleOCR/
|
||||
wget https://paddleocr.bj.bcebos.com/dygraph_v2.1/kie/kie_vgg16.tar && tar xf kie_vgg16.tar
|
||||
python3.7 tools/infer_kie.py -c configs/kie/kie_unet_sdmgr.yml -o Global.checkpoints=kie_vgg16/best_accuracy Global.infer_img=../wildreceipt/1.txt
|
||||
```
|
||||
|
||||
The prediction result is saved as the folder`./output/sdmgr_kie/predicts_kie.txt`,the visualization result is saved as the folder`/output/sdmgr_kie/kie_results/`。
|
||||
|
||||
Visualization Result Figures:
|
||||
|
||||
<div align="center">
|
||||
<img src="./imgs/0.png" width="800">
|
||||
</div>
|
||||
|
||||
<a name="2-----"></a>
|
||||
## 2. Execution Training
|
||||
|
||||
Building dataset link to PaddleOCR/train_data:
|
||||
|
||||
```
|
||||
cd PaddleOCR/ && mkdir train_data && cd train_data
|
||||
ln -s ../../wildreceipt ./
|
||||
```
|
||||
The training using configure file is configs/kie/kie_unet_sdmgr.yml,configure file default train path is `train_data/wildreceipt`, when prepare train data using as below command execute
|
||||
training:
|
||||
```
|
||||
python3.7 tools/train.py -c configs/kie/kie_unet_sdmgr.yml -o Global.save_model_dir=./output/kie/
|
||||
```
|
||||
<a name="3-----"></a>
|
||||
## 3. Execution Evaluation
|
||||
|
||||
```
|
||||
python3.7 tools/eval.py -c configs/kie/kie_unet_sdmgr.yml -o Global.checkpoints=./output/kie/best_accuracy
|
||||
```
|
||||
|
||||
|
||||
**Reference Documents:**
|
||||
|
||||
<!-- [ALGORITHM] -->
|
||||
|
||||
```bibtex
|
||||
@misc{sun2021spatial,
|
||||
title={Spatial Dual-Modality Graph Reasoning for Key Information Extraction},
|
||||
author={Hongbin Sun and Zhanghui Kuang and Xiaoyu Yue and Chenhao Lin and Wayne Zhang},
|
||||
year={2021},
|
||||
eprint={2103.14470},
|
||||
archivePrefix={arXiv},
|
||||
primaryClass={cs.CV}
|
||||
}
|
||||
```
|
||||
Loading…
Reference in New Issue